-
Play with ChatGPT API
Shell
curl https://api.openai.com/v1/chat/completions \ -H 'Content-Type: application/json' \ -H 'Authorization: Bearer $OPENAI_API_KEY' \ -d '{ "model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "Hello!"}] }'Python
这里介绍了三个角色,完整的用法是三个都用,正如 Assistant Role 代码所示。
-
文生图技术分享
OpenAI 的文本生成模型 DALL-E 2 一经推出,就在社交媒体上引起了轰动,我当时正为即将轮到本人的团队技术分享寻找主题,分享内容可以跟自己项目毫无关系,于是我选择了分享文本生成模型 DALL-E 2,从原始论文延展到相关技术细节,读了大量论文和网络技术分享。准备这个分享时是七八月份,但因为疫情原因不断居家办公,最终在公司分享时已经到了 12 月底,ChatGPT 都已经发布了,好在最终圆满完成任务。
-
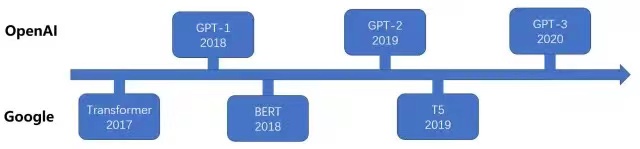
Transformer Family
-
车辆调度问题概述
车辆调度问题,英文是 Vehicle Routing Problem,简称 VRP,一般翻译成车辆路径问题。主要解决物流公司的痛点,怎么用最小成本把仓库的货物分发到各个站点。
-
BM25 调参调研
搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景
-
大作业-电影推荐系统
电影推荐系统
推荐系统的文献汗牛充栋,大家对此应该都不陌生。之所以选这个题目一是简单,在一周多晚上十点以后的自由时间里,只有选简单的题目才能完成,即便如此,依然捉襟见肘;二是希望好好研究下数据,一步步推到推荐系统的设计,而不是像以前直奔算法,当然也是时间原因,这里对数据的探索也是远远不够的。
本文前面探索阶段所用的数据集太大,导致多个分析运行一天也出不了结果,所以后面在推荐系统的建模中,又换成了较小的 MovieLens 1M 数据集。
-
机器学习初步学习笔记
注:该文是上了开智学堂数据科学入门班的课后做的笔记,主讲人是肖凯老师。
机器学习初步
机器学习基本概念
机器学习、统计模型和数据挖掘有什么异同?
机器学习和统计模型区别不是很大,机器学习和统计模型中的回归都一样,底层算法都是差不多的,只是侧重点不一样,在统计学的角度,回归主要解决的问题侧重点在于模型的解释能力,关注的是 x 和 y 之间的关系,关注的更多是系数,从机器学习的角度看,关注的重点是预测的准确性。
-
机器学习初步练习题
1. 写一个函数,能将一个多类别变量转为多个二元虚拟变量,不能使用 sklearn 库。
-
线性模型学习笔记
注:该文是根据开智学堂数据科学入门班的讲课内容整理而成,主讲人是肖凯老师。
线性模型
主要学习用 statsmodels 模块进行线性回归、逻辑回归和时间序列分析。
线性模型基本概念
多个因素的定量化计算,是线性模型的最主要用途。
-
线性模型练习题
1. 学习理解如何用最小二乘法的矩阵公式来得到线性回归的解,并使用numpy库来实现该算法。
在研究一个问题时,从某种理论或假定出发,得到一个模型。根据这个模型,我们感兴趣的某个量有其理论值,同时可以对这个量进行实际观测,而得出其观测值。由于种种原因,如模型不完全正确以及观测有误差,理论值与观测值会有差距,这差距的平方和
Recent Posts
Categories
Tags