-
趣谈情商与AI
AI 中欠拟合和过拟合的概念跟情商有着相似的底层原理,从 AI 的角度看情商可以把情商分析得更透彻清晰。
-
具身智能仿真踩坑记
心血来潮想玩下机器人仿真 NVIDIA Isaac Sim,想来英伟达出品,必定 so easy,结果光安装就把我干吐血了,灰头土脸。
-
长音频转阅读体验极佳的文字
如何将长达三个小时的音频转成适宜阅读的文字
-
多轮对话评估框架-intellagent
IntellAgent 是一个多智能体框架,专门用于评估和优化对话式AI系统。
-
Automatic Prompt Optimization-PromptWizard
本文不是 PromptWizard 代码解读,而是来看 Prompt 是如何通过 meta prompt 一步步优化的。至于进化机制原理,大家都懂,不必啰嗦,重要的是 meta prompt。
-
语音大模型技术详解:主流开源方案架构对比
本文系统性地分析了2024年以来具有代表性的7个开源语音大模型,包括Moshi、Mini-Omni、Freeze-Omni、GLM-4-Voice、MiniCPM-o、Step-Audio和Qwen2.5 Omni(其中MiniCPM-o和Qwen2.5 Omni作为多模态模型,我们重点探讨其语音交互模块)。受限于研究范围,部分同期项目暂未纳入本次讨论。基于官方技术报告、开源代码及模型权重,我们对这些模型的架构进行了深入的技术解构,通过白盒化的分析方法,旨在帮助读者快速把握语音大模型的技术精髓,并为后续研究或工程落地提供可复用的方法论。
-
语音到语音的旅程-暴拆GLM-4-Voice
本文基于 GLM-4-Voice 论文及开源代码,从计算工作流的角度,仔细梳理在Speech->GLM-4-Voice->Speech过程中,信息都经过了哪些处理及变化,从而对语音端到端的计算过程有个深切的理解,或许会从这些计算的细节中发觉出智能诞生的奥秘。
-
Transformer Q&A
Input Embedding
Q: Embedding层包含哪些参数?
A: 这部分参数包括输入和输出的 token embeddings 以及 positional encodings。token embeddings将 tokens 映射到高维空间,而 positional encodings 则为模型提供序列中每个元素的位置信息。在大型模型中,由于词汇表的大小和序列长度的增加,这部分参数量会占据相当的比例。当然位置编码不一定增加参数量,要看是固定函数生成还是训练得到的参数。
-
多模态论文梳理
因项目需要,梳理了截止到2023年6月底的多模态论文。
-
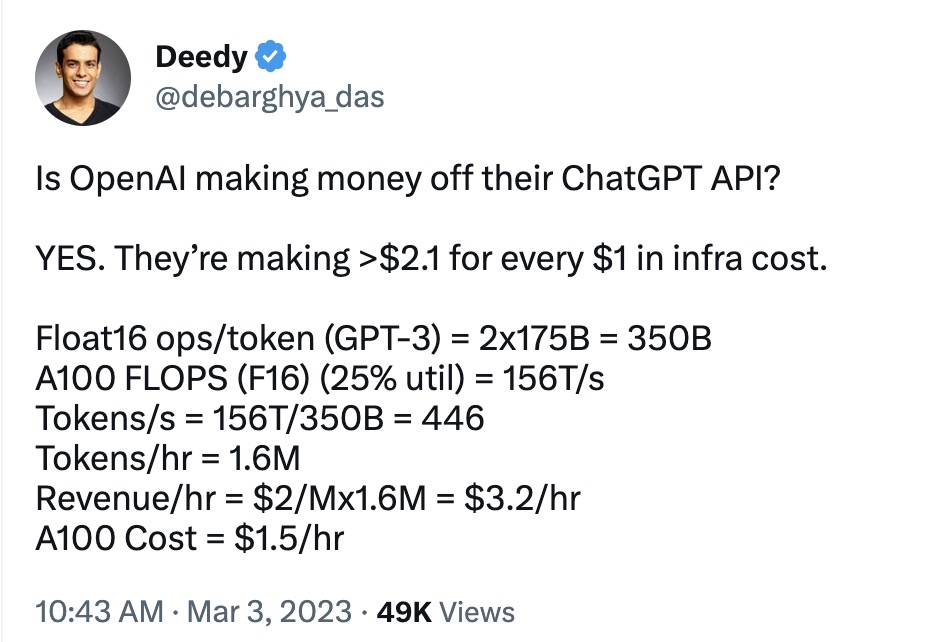
ChatGPT API 赚钱吗?
Recent Posts
Categories
Tags