简介
GLM-4-Voice 是智谱推出的端到端语音模型,能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。本文基于 GLM-4-Voice 论文及开源代码,从计算工作流的角度,仔细梳理在Speech->GLM-4-Voice->Speech过程中,信息都经过了哪些处理及变化,从而对语音端到端的计算过程有个深切的理解,或许会从这些计算的细节中发觉出智能诞生的奥秘。
架构之美
GLM-4-Voice 是一个语音语言模型(speech language model, SLM),主要由Speech Tokenizer、LLM、Speech Decoder三个模块组成。输入端支持语音输入,输出端支持文本和语音交替输出,其中输出的文本是为了引导后续的语音片段输出。
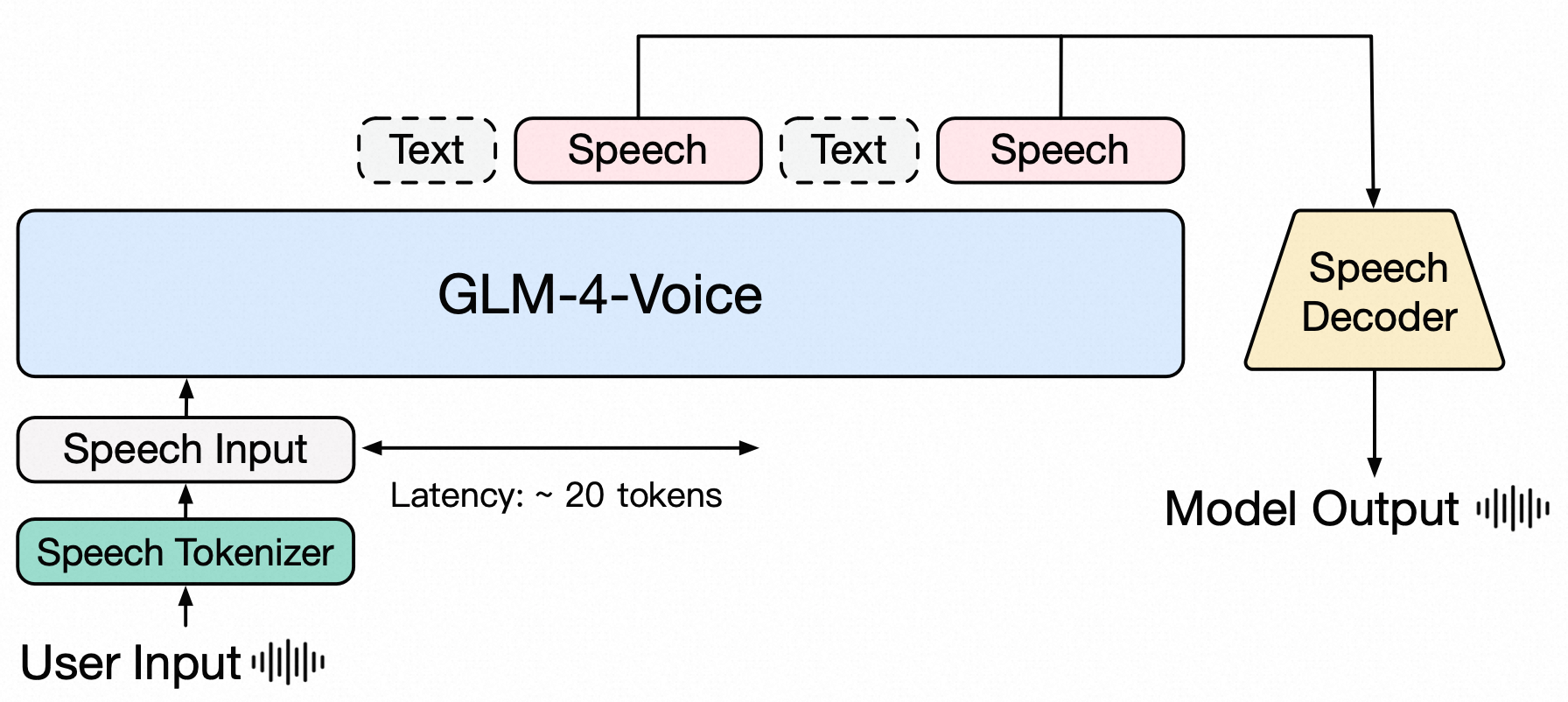
下面会重点介绍Speech Tokenizer 和 Speech Decoder 的模型架构,GLM-4-Voice 在这两块所采用的方案在业界具有一定代表性,同时也是很多不熟悉语音模态处理的同学的知识盲区,所以会多花点篇幅介绍。而LLM 的模型架构由于业界相对统一,大家都比较熟悉,所以不会过多介绍,了解其 Prompt 设计和 LLM Tokenization即可。
Speech Tokenizaion
GLM-4-Voice-Tokenizer 通过在 Whisper 的 Encoder 部分增加 Vector Quantization,将连续的语音输入转化为离散的 token,每秒音频平均只需要用 12.5 个离散 token 表示。为实现输入语音流式编码,在推理过程中调整了Whisper编码器的架构以引入causality,包括用causal convolution 替换 encoder 前的卷积层,并将编码器中的 bidirectional attention 替换为 block causal attention。下图是 Speech Tokenizaion 主要算法结构,不包含音频数据预处理部分。
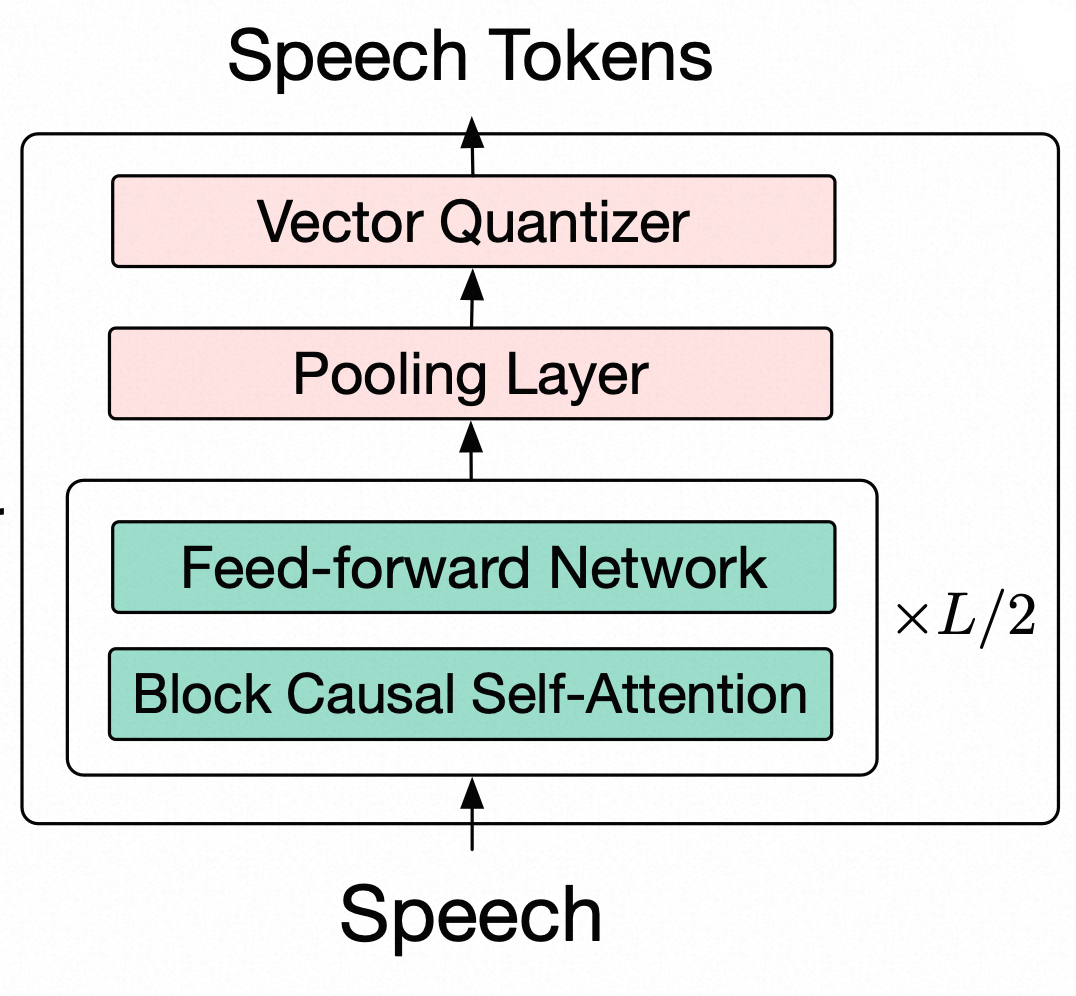
GLM-4-Voice-Tokenizer 使用了一批 ASR 数据集来训练,详情参考论文,这里不再赘述。
下面详细分析一下从音频输入到音频 Tokenizaion 模型输出的整个过程,包括每一步的矩阵大小和信息的转化。
音频采样
- 输入:音频数据(介绍方便起见,这里假设输入 30 秒音频数据)
- torchaudio.load 将音频数据归一化到 [-1.0, 1.0] 的浮点数范围,以便于后续处理
- 如果采样率不是 16kHz,则需进行重采样为 16kHz
- 只取音频的第一个通道(单声道),并将其转换为 NumPy 数组
- 将音频数据分割成 30 秒的片段(30 秒对应 16000 × 30 = 480000 个采样点)
- 输出:(480000,) 的音频波形(这里假设 batch_size=1,忽略 batch_size)
特征提取
对音频进行特征提取,主要是将音频转换为梅尔频谱图(Mel-spectrogram)。下面介绍过程中涉及参数均采用官方配置,如下代码所示。
>>> tokenizer_path = "THUDM/glm-4-voice-tokenizer"
>>> feature_extractor = WhisperFeatureExtractor.from_pretrained(tokenizer_path)
>>> feature_extractor
WhisperFeatureExtractor {
"chunk_length": 30,
"feature_extractor_type": "WhisperFeatureExtractor",
"feature_size": 128,
"hop_length": 160,
"n_fft": 400,
"n_samples": 480000,
"nb_max_frames": 3000,
"padding_side": "right",
"padding_value": 0.0,
"processor_class": "WhisperProcessor",
"return_attention_mask": false,
"sampling_rate": 16000
}
其中关键参数含义:
- hop_length = 160:跳数,STFT(短时傅里叶变换)的帧移,即每一帧向前移动 160 个采样点
- n_fft = 400:帧长, 也即FFT窗口的大小,这里为 400
- feature_size = 128:特征维度,也即n_mels,表示梅尔滤波器组的数量,也就是梅尔频谱图的频带数,这里为 128
- sampling_rate = 16000:音频采样率为 16kHz
梅尔频谱图的生成过程如下:
- 输入:音频波形,形状为 (480000,)
- 分帧:将音频信号分割为多个帧,每帧的长度为 n_fft(400 个采样点),相邻帧之间的间隔是 hop_length(160 个采样点),因此,帧之间的重叠量为 帧长−跳数=400−160=240 个采样点,对于 30 秒的音频,总帧数 n_frames 为 ⌊(480000 - 400) / 160⌋ + 1 = 3000
- 加窗:对每一帧信号应用汉明窗(Hamming Window),以减少频谱泄漏
- 短时傅里叶变换(STFT):对每一帧加窗后的信号进行快速傅里叶变换(FFT),将时域信号转换为频域信号。FFT 的输出是一个复数矩阵,形状为 (n_frames, n_fft // 2 + 1),这里即 (3000, 400 // 2 + 1) = (3000, 201),矩阵中的复数表示每个频率成分的幅度和相位。
- 计算功率谱:对 FFT 的复数结果取模的平方,得到功率谱(Power Spectrum),功率谱表示每个频率成分的能量,功率谱的形状仍为 (n_frames, n_fft // 2 + 1) = (3000, 201)
- 梅尔滤波器组:将功率谱通过一组梅尔滤波器(Mel Filter Bank),将线性频率刻度转换为梅尔频率刻度,因为梅尔频率更接近人耳对音高的感知。梅尔滤波器组的形状为 (n_mels, n_fft // 2 + 1) = (128, 201),这里 n_mels = 128,每个梅尔滤波器对应一个频带,输出是该频带内的能量总和。经过梅尔滤波器组后,输出的形状为 (n_frames, n_mels),即 (3000, 128)。
- 对数变换:对梅尔滤波器组的输出取对数,得到对数梅尔频谱。对数变换的目的是压缩动态范围,使得较小的能量值也能被有效表示。最终输出的梅尔频谱图形状为 (3000, 128)
- 输出:梅尔频谱图,形状为 (3000, 128)
Tokenizaion模型推理
这里 Tokenizer 模型是在 Whisper 的 Encoder 部分增加了 Vector Quantization。
>>> tokenizer_path = "THUDM/glm-4-voice-tokenizer"
>>> whisper_model = WhisperVQEncoder.from_pretrained(tokenizer_path).eval()
>>> whisper_model
WhisperVQEncoder(
(conv1): CausalConv1d(128, 1280, kernel_size=(3,), stride=(1,))
(conv2): CausalConv1d(1280, 1280, kernel_size=(3,), stride=(2,))
(embed_positions): Embedding(1500, 1280)
(layers): ModuleList(
(0-15): 16 x WhisperVQEncoderLayer(
(self_attn): WhisperSdpaAttention(
(k_proj): Linear(in_features=1280, out_features=1280, bias=False)
(v_proj): Linear(in_features=1280, out_features=1280, bias=True)
(q_proj): Linear(in_features=1280, out_features=1280, bias=True)
(out_proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(self_attn_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1280, out_features=5120, bias=True)
(fc2): Linear(in_features=5120, out_features=1280, bias=True)
(final_layer_norm): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
)
)
(pooling_layer): AvgPool1d(kernel_size=(4,), stride=(4,), padding=(0,))
(codebook): Embedding(16384, 1280)
(embed_positions2): Embedding(375, 1280)
)
对照上面 Tokenizer 模型结构,推理过程简述如下:
- 第一层卷积 (conv1):输入梅尔频谱图,形状为 (3000, 128),输出形状为 (3000, 1280)
- 第二层卷积 (conv2):输出形状为 (1500, 1280)
- 多层Transformer编码器:输出形状为 (1500, 1280)
- 池化层:输出形状为 (375, 1280)
- 量化过程:对于每个池化层的输出特征向量(形状为 (1280,)),计算它与码本中所有向量(16384 个)的距离。通常使用欧几里得距离(L2 距离)来衡量相似性。选择距离最小的码本向量,并记录其索引。对形状为 (375, 1280) 的输出特征矩阵中的每个向量(共 375 个)重复上述过程,得到 375 个索引。
- 最终输出:形状为 (375,) 的索引向量,每个值是一个整数,范围是从 0 到 16383,表示对应特征向量在码本中的索引。
这里将 30 秒的音频转为 375 个 token,即平均每秒 12.5 个 token。
Speech LLM
LLM 部分即 GLM-4-Voice-9B,是基于 GLM-4-9B 做的语音模态预训练和对齐,从而能够理解和生成离散化的语音 token,即 。这里分为 Prompt 构造、Tokenizaion、模型推理三部分介绍。
Prompt 构造
Prompt 由 System Prompt 和 User Prompt(即音频 token)组成,如下代码所示。
# 添加 System Prompt
system_prompt = "User will provide you with a speech instruction. Do it step by step. First, think about the instruction and respond in a interleaved manner, with 13 text token followed by 26 audio tokens. "
inputs = f"<|system|>\n{system_prompt}"
# 添加 User Prompt
# 输入 audio_tokens 即为形状为 (375,) 的索引向量
audio_tokens = "".join([f"<|audio_{x}|>" for x in audio_tokens])
audio_tokens = "<|begin_of_audio|>" + audio_tokens + "<|end_of_audio|>"
user_input = audio_tokens
inputs += f"<|user|>\n{user_input}<|assistant|>streaming_transcription\n"
- System Prompt 指示 LLM 交替生成13个文本标记和26个语音标记,要求文本生成早于语音。
- 将 audio_tokens 中的索引值拼成 <|audio_{x}|> 标识,以备后续 Tokenizaion
- 拼接 System Prompt 和 User Prompt,输出给后续 Tokenizaion
LLM Tokenizaion
Token 库中前 151329 是文本 token,即 token id 从 0 到 151328,然后 token id 从 151329 到 151346 是附加的特殊 token,token id 从 151347 到 152352 是保留 token,从 152353 到 168735 的 16383 个 token id 即音频专属区域。
>>> model_path = "THUDM/glm-4-voice-9b"
>>> glm_tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
>>> print(f"Vocabulary Size: {glm_tokenizer.vocab_size}")
Vocabulary Size: 151329
>>> print(f"total_vocab_size: {glm_tokenizer.total_vocab_size}")
total_vocab_size: 168736
>>> inputs = tokenizer(inputs, return_tensors="pt") // 此入参 inputs 即由上文 System Prompt 和 User Prompt 拼接而成
这里将包含 System Prompt 和 User Prompt 拼接串转成 glm-4-voice-9b 词库中对应的 token id,其中包含 375 个音频 token。
LLM模型推理
GLM-4-Voice-9B 模型结构如下示例代码。
>>> from transformers import AutoModel
>>> model_path = "THUDM/glm-4-voice-9b"
>>> glm_model = AutoModel.from_pretrained(model_path)
>>> glm_model
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(168960, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-39): 40 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): SdpaAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=168960, bias=False)
)
)
LLM Tokenizaion 环节输出的 token id 序列输入 glm_model,经过模型推理,输出预测的 token id 序列,从中分别取出 text_tokens 和 audio_tokens,text_tokens 解码后加入 history,audio_tokens 输入下一步的 Speech Decoder 环节。根据官方文档,最少只需要生成 10 个语音 token 即可开始Speech Decoder 。
Speech Decoder
GLM-4-Voice 的 Speech Decoder,是基于 CosyVoice 重新训练的支持流式推理的语音解码器,将语音 token 转化为连续的语音输出。最少只需要 10 个音频 token 即可开始生成,降低对话延迟。 将 LLM 输出的 token 转换为音频波形(wav)。这个过程主要依赖于两个模型:Flow Matching 和 HiFi-GAN Vocoder。Flow Matching 模型负责将输入的 token 转换为梅尔频谱(mel-spectrogram),而 HiFi-GAN Vocoder 模型则将梅尔频谱转换为音频波形。
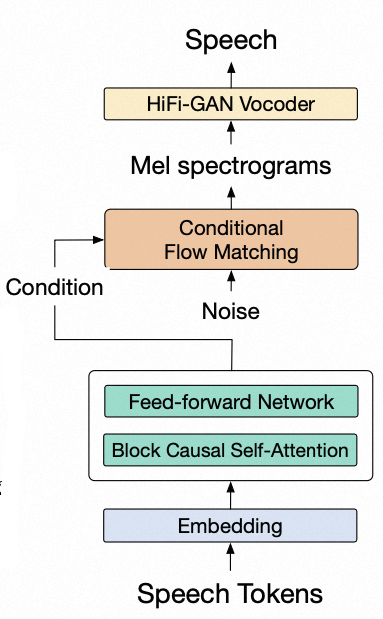
Flow Matching
Flow Matching 模型负责将输入的 token 转换为梅尔频谱(mel-spectrogram)。
模型结构主要包含两部分,encoder 和 decoder。encoder 使用 Transformer 编码器将离散 token 序列转换为contextual vectors。decoder(Flow matching model)基于 speech token representations 生成 Mel spectrograms。 下面记录了详细的模型结构,以便于读者做更深入细致的分析。如只想了解大致计算过程,可跳过该代码。
>>> flow_path = "./glm-4-voice-decoder"
>>> flow_config = os.path.join(flow_path, "config.yaml")
>>> flow_checkpoint = os.path.join(flow_path, 'flow.pt')
>>> hift_checkpoint = os.path.join(flow_path, 'hift.pt')
>>> audio_decoder = AudioDecoder(config_path=flow_config, flow_ckpt_path=flow_checkpoint,hift_ckpt_path=hift_checkpoint, device=device)
>>> print(audio_decoder.flow)
MaskedDiffWithXvec(
(input_embedding): Embedding(16384, 512)
(spk_embed_affine_layer): Linear(in_features=192, out_features=80, bias=True)
(encoder): BlockConformerEncoder(
(embed): LinearNoSubsampling(
(out): Sequential(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(2): Dropout(p=0.1, inplace=False)
)
(pos_enc): EspnetRelPositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(after_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(encoders): ModuleList(
(0-5): 6 x ConformerEncoderLayer(
(self_attn): BlockRelPositionMultiHeadedAttention(
(linear_q): Linear(in_features=512, out_features=512, bias=True)
(linear_k): Linear(in_features=512, out_features=512, bias=True)
(linear_v): Linear(in_features=512, out_features=512, bias=True)
(linear_out): Linear(in_features=512, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear_pos): Linear(in_features=512, out_features=512, bias=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=512, out_features=2048, bias=True)
(activation): SiLU()
(dropout): Dropout(p=0.1, inplace=False)
(w_2): Linear(in_features=2048, out_features=512, bias=True)
)
(norm_ff): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(norm_mha): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(encoder_proj): Linear(in_features=512, out_features=80, bias=True)
(decoder): ConditionalCFM(
(estimator): ConditionalDecoder(
(time_embeddings): SinusoidalPosEmb()
(time_mlp): TimestepEmbedding(
(linear_1): Linear(in_features=320, out_features=1024, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=1024, out_features=1024, bias=True)
)
(down_blocks): ModuleList(
(0): ModuleList(
(0): ResnetBlock1D(
(mlp): Sequential(
(0): Mish()
(1): Linear(in_features=1024, out_features=256, bias=True)
)
(block1): Block1D(
(block): Sequential(
(0): Conv1d(320, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(block2): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(res_conv): Conv1d(320, 256, kernel_size=(1,), stride=(1,))
)
(1): ModuleList(
(0-3): 4 x BasicTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): Linear(in_features=256, out_features=512, bias=False)
(to_k): Linear(in_features=256, out_features=512, bias=False)
(to_v): Linear(in_features=256, out_features=512, bias=False)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Dropout(p=0, inplace=False)
)
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=256, out_features=1024, bias=True)
)
(1): Dropout(p=0, inplace=False)
(2): LoRACompatibleLinear(in_features=1024, out_features=256, bias=True)
)
)
)
)
(2): Downsample1D(
(conv): Conv1d(256, 256, kernel_size=(3,), stride=(2,), padding=(1,))
)
)
(1): ModuleList(
(0): ResnetBlock1D(
(mlp): Sequential(
(0): Mish()
(1): Linear(in_features=1024, out_features=256, bias=True)
)
(block1): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(block2): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(res_conv): Conv1d(256, 256, kernel_size=(1,), stride=(1,))
)
(1): ModuleList(
(0-3): 4 x BasicTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): Linear(in_features=256, out_features=512, bias=False)
(to_k): Linear(in_features=256, out_features=512, bias=False)
(to_v): Linear(in_features=256, out_features=512, bias=False)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Dropout(p=0, inplace=False)
)
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=256, out_features=1024, bias=True)
)
(1): Dropout(p=0, inplace=False)
(2): LoRACompatibleLinear(in_features=1024, out_features=256, bias=True)
)
)
)
)
(2): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(mid_blocks): ModuleList(
(0-11): 12 x ModuleList(
(0): ResnetBlock1D(
(mlp): Sequential(
(0): Mish()
(1): Linear(in_features=1024, out_features=256, bias=True)
)
(block1): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(block2): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(res_conv): Conv1d(256, 256, kernel_size=(1,), stride=(1,))
)
(1): ModuleList(
(0-3): 4 x BasicTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): Linear(in_features=256, out_features=512, bias=False)
(to_k): Linear(in_features=256, out_features=512, bias=False)
(to_v): Linear(in_features=256, out_features=512, bias=False)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Dropout(p=0, inplace=False)
)
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=256, out_features=1024, bias=True)
)
(1): Dropout(p=0, inplace=False)
(2): LoRACompatibleLinear(in_features=1024, out_features=256, bias=True)
)
)
)
)
)
)
(up_blocks): ModuleList(
(0): ModuleList(
(0): ResnetBlock1D(
(mlp): Sequential(
(0): Mish()
(1): Linear(in_features=1024, out_features=256, bias=True)
)
(block1): Block1D(
(block): Sequential(
(0): Conv1d(512, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(block2): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(res_conv): Conv1d(512, 256, kernel_size=(1,), stride=(1,))
)
(1): ModuleList(
(0-3): 4 x BasicTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): Linear(in_features=256, out_features=512, bias=False)
(to_k): Linear(in_features=256, out_features=512, bias=False)
(to_v): Linear(in_features=256, out_features=512, bias=False)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Dropout(p=0, inplace=False)
)
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=256, out_features=1024, bias=True)
)
(1): Dropout(p=0, inplace=False)
(2): LoRACompatibleLinear(in_features=1024, out_features=256, bias=True)
)
)
)
)
(2): Upsample1D(
(conv): ConvTranspose1d(256, 256, kernel_size=(4,), stride=(2,), padding=(1,))
)
)
(1): ModuleList(
(0): ResnetBlock1D(
(mlp): Sequential(
(0): Mish()
(1): Linear(in_features=1024, out_features=256, bias=True)
)
(block1): Block1D(
(block): Sequential(
(0): Conv1d(512, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(block2): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(res_conv): Conv1d(512, 256, kernel_size=(1,), stride=(1,))
)
(1): ModuleList(
(0-3): 4 x BasicTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn1): Attention(
(to_q): Linear(in_features=256, out_features=512, bias=False)
(to_k): Linear(in_features=256, out_features=512, bias=False)
(to_v): Linear(in_features=256, out_features=512, bias=False)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=256, bias=True)
(1): Dropout(p=0, inplace=False)
)
)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=256, out_features=1024, bias=True)
)
(1): Dropout(p=0, inplace=False)
(2): LoRACompatibleLinear(in_features=1024, out_features=256, bias=True)
)
)
)
)
(2): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(final_block): Block1D(
(block): Sequential(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(8, 256, eps=1e-05, affine=True)
(2): Mish()
)
)
(final_proj): Conv1d(256, 80, kernel_size=(1,), stride=(1,))
)
)
(length_regulator): InterpolateRegulator(
(model): Sequential(
(0): Conv1d(80, 80, kernel_size=(3,), stride=(1,), padding=(1,))
(1): GroupNorm(1, 80, eps=1e-05, affine=True)
(2): Mish()
(3): Conv1d(80, 80, kernel_size=(3,), stride=(1,), padding=(1,))
(4): GroupNorm(1, 80, eps=1e-05, affine=True)
(5): Mish()
(6): Conv1d(80, 80, kernel_size=(3,), stride=(1,), padding=(1,))
(7): GroupNorm(1, 80, eps=1e-05, affine=True)
(8): Mish()
(9): Conv1d(80, 80, kernel_size=(3,), stride=(1,), padding=(1,))
(10): GroupNorm(1, 80, eps=1e-05, affine=True)
(11): Mish()
(12): Conv1d(80, 80, kernel_size=(1,), stride=(1,))
)
)
)
>>> tts_mel = audio_decoder.flow.inference(token=audio_tokens, prompt_token=flow_prompt_speech_token, prompt_feat=prompt_speech_feat, embedding=torch.zeros(1, 192)) #这里的 audio_tokens 已经减去了 audio_offset,还原成 Speech Tokenizaion 时的 token id
根据模型结构和Demo代码,推理计算的大致过程如下:
- 输入:
- token:输入的音频 token, 形状为 (1, token_length) 的整数张量
- prompt_token:之前的音频 token 序列,用于提供上下文信息或引导生成过程,形状为 (1, prompt_token_length) 的整数张量
- prompt_feat:与 prompt_token 对应的梅尔频谱特征,即当前 token 之前生成的梅尔频谱特征,形状为 (1, prompt_feat_length, 80) 的浮点数张量
- embedding:表示说话者的特征或风格信息,这里没用,所以固定为 torch.zeros(1, 192)
- Embedding:
- Token Embedding:token 经过 input_embedding 后,形状变为 (1, token_length, 512),prompt_token 经过 input_embedding 后,形状变为 (1, prompt_token_length, 512)
- Speaker Embedding:通过 spk_embed_affine_layer 将 192 维的嵌入向量映射为 80 维的特征。输出形状为 (1, 80) 的浮点数张量,后续通过线性变换和特征拼接的方式融入 Encoder 的编码过程,因为这里没用到,所以下文不再赘述。
- Encoder 编码:
- 拼接:将 token 和 prompt_token 在序列维度上拼接,得到形状为 (1, token_length + prompt_token_length, 512) 的张量。
- 编码:encoder 是一个 BlockConformerEncoder,包含多个 ConformerEncoderLayer,每个 ConformerEncoderLayer 包含自注意力机制(Self-Attention)、前馈网络(FeedForward)和卷积模块。编码过程中,序列长度保持不变,特征维度从 512 维经过多层变换后仍为 512 维。输出形状为 (1, token_length + prompt_token_length, 512) 的浮点数张量。
- 投影:通过 encoder_proj 将 512 维特征映射为 80 维特征。输出形状为 (1, token_length + prompt_token_length, 80) 的浮点数张量。
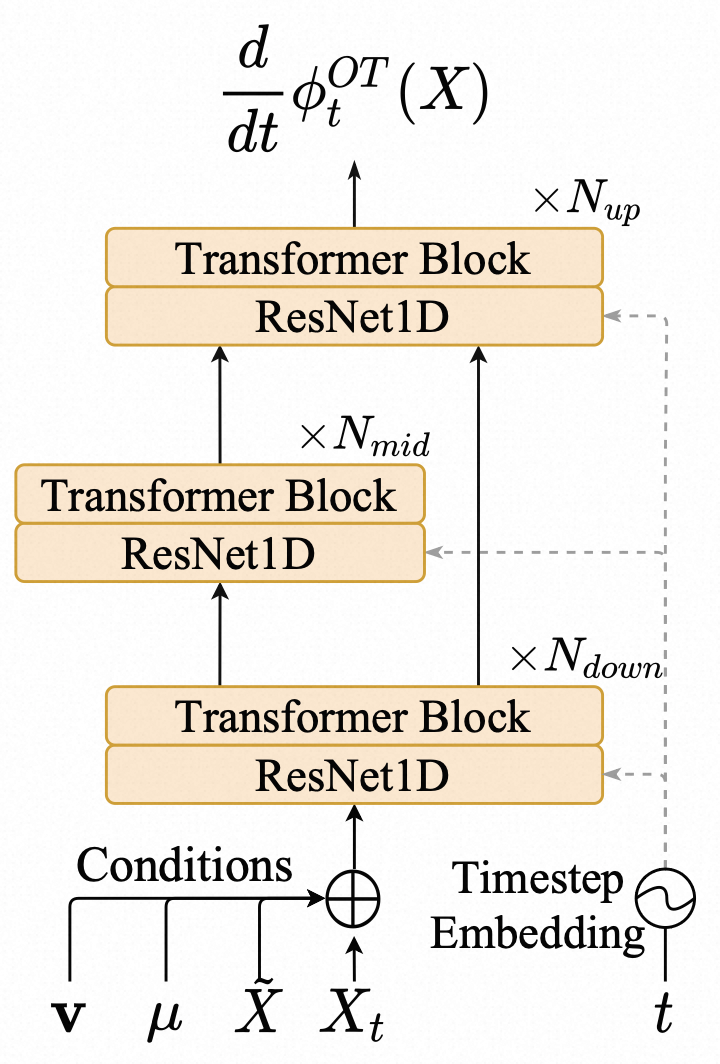
- Decoder 解码:decoder 是一个 ConditionalCFM 模型,包含多个残差块和上采样层。
- 下采样块(Down Blocks):通过 ConditionalDecoder 的 down_blocks 进行下采样,降低序列长度,提取高层次特征。(1, token_length + prompt_token_length, 512) -> (1, (token_length + prompt_token_length) / 2, 256)
- 中间块(Mid Blocks):进一步提取特征,保持序列长度不变。(1, downsampled_length, 256) -> (1, downsampled_length, 256)。其中downsampled_length = (token_length + prompt_token_length) / 2
- 上采样块(Up Blocks): 增加序列长度,恢复细节信息。(1, downsampled_length, 256) -> (1, downsampled_length * 2, 256)
- 最终块(Final Block): 通过 final_block 和 final_proj 生成最终的梅尔频谱。(1, upsampled_length, 256) -> (1, 80, mel_length)。其中mel_length=upsampled_length= token_length + prompt_token_length。
- 输出: 形状为 (1, 80, mel_length) 的浮点数张量,表示生成的梅尔频谱。
HiFi-GAN Vocoder
HiFi-GAN Vocoder 模型负责将梅尔频谱转换为音频波形。
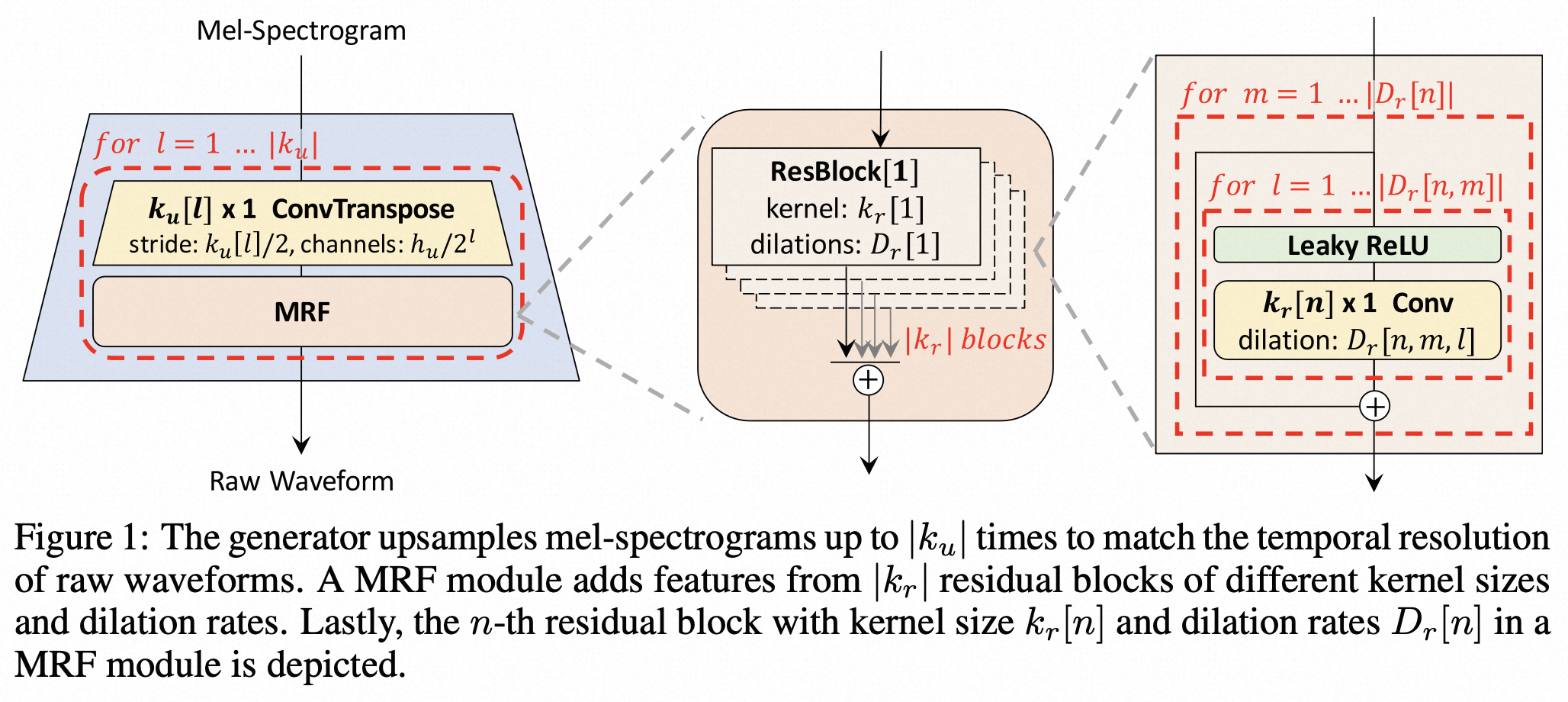
下面记录了详细的模型结构,如只想了解大致计算过程,可略过该代码。
>>> print(audio_decoder.hift)
HiFTGenerator(
(m_source): SourceModuleHnNSF(
(l_sin_gen): SineGen()
(l_linear): Linear(in_features=9, out_features=1, bias=True)
(l_tanh): Tanh()
)
(f0_upsamp): Upsample(scale_factor=256.0, mode='nearest')
(conv_pre): Conv1d(80, 512, kernel_size=(7,), stride=(1,), padding=(3,))
(ups): ModuleList(
(0): ConvTranspose1d(512, 256, kernel_size=(16,), stride=(8,), padding=(4,))
(1): ConvTranspose1d(256, 128, kernel_size=(16,), stride=(8,), padding=(4,))
)
(source_downs): ModuleList(
(0): Conv1d(18, 256, kernel_size=(16,), stride=(8,), padding=(4,))
(1): Conv1d(18, 128, kernel_size=(1,), stride=(1,))
)
(source_resblocks): ModuleList(
(0): ResBlock(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(1): ResBlock(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
)
(resblocks): ModuleList(
(0): ResBlock(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(1): ResBlock(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(2): ResBlock(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(5,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(3): ResBlock(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(4): ResBlock(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(3,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
(5): ResBlock(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
)
(activations1): ModuleList(
(0-2): 3 x Snake()
)
(activations2): ModuleList(
(0-2): 3 x Snake()
)
)
)
(conv_post): Conv1d(128, 18, kernel_size=(7,), stride=(1,), padding=(3,))
(reflection_pad): ReflectionPad1d((1, 0))
(f0_predictor): ConvRNNF0Predictor(
(condnet): Sequential(
(0): Conv1d(80, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(1): ELU(alpha=1.0)
(2): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(3): ELU(alpha=1.0)
(4): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(5): ELU(alpha=1.0)
(6): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(7): ELU(alpha=1.0)
(8): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(9): ELU(alpha=1.0)
)
(classifier): Linear(in_features=512, out_features=1, bias=True)
)
)
>>> tts_speech, tts_source = self.hift.inference(mel=tts_mel, cache_source=hift_cache_source)
根据模型结构和Demo代码,推理计算的大致过程如下:
- 输入:形状为 (1, 80, mel_length) 的浮点数张量,表示梅尔频谱
- 预处理层 (conv_pre):卷积操作,输出形状 (1, 512, mel_length)
- 上采样层 (ups):通过两个 ConvTranspose1d 层,进行两次上采样操作,输出形状 (1, 128, mel_length * 64)
- 残差块 (resblocks):通过多个残差块,进行特征提取,每个残差块包含多个卷积层和激活函数,保持输入输出形状不变,输出形状:(1, 128, mel_length * 64)
- 后处理层 (conv_post):卷积操作,输出形状 (1, 18, mel_length * 64)
- 反射填充层 (reflection_pad):输出形状 (1, 18, mel_length * 64 + 1)
- F0 预测器 (f0_predictor):进行 F0 预测和音频波形生成,输出形状 (1, audio_length),其中 audio_length=mel_length * 64
- 输出:音频波形 (1, audio_length)
通过以上步骤,hift.inference 将输入的梅尔频谱转换为音频波形 tts_speech。
训练方法
如果以人来比对模型,那么模型架构属于先天条件,先天大脑硬件配置当然很重要,但后天的训练学习也同样不可或缺,不管是预训练还是微调,都属于后天训练学习。Speech Tokenization 和 Speech Decoder 的训练是独立的前置训练模块,GLM-4-Voice 对 LLM 的训练分为 Joint Speech-Text Pre-training 和 Supervised Fine-tuning 两个阶段。
Joint Speech-Text Pre-training
GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。
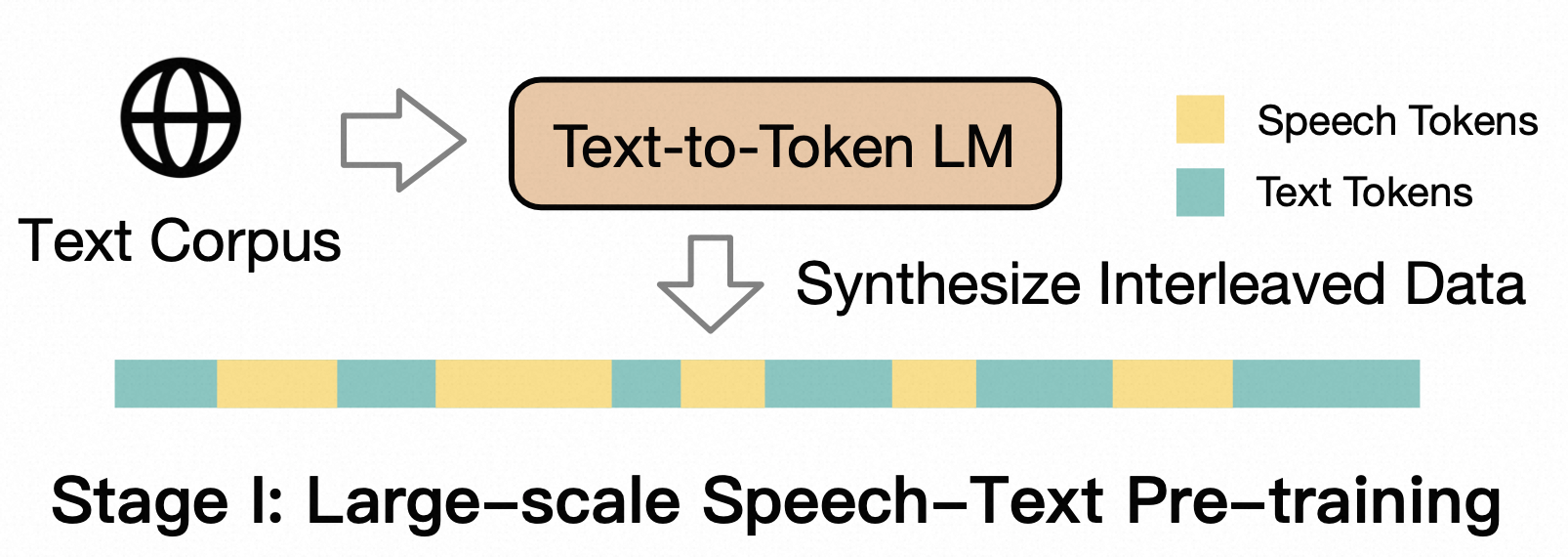
这一步的目标是通过大规模语音预训练扩展LLM的语音能力,主要使用如下三种数据:
- Interleaved speech-text data:作者团队在另一项工作中由文本预训练数据合成的语音-文本交错数据,促进文本和语音之间的跨模态知识转移。
- Unsupervised speech data:包括70万小时的语音数据,鼓励模型从现实世界的语音中学习。
- Supervised speech-text data:包括 ASR 和 TTS 数据,提高模型在基本语音任务中的能力。 另外,为保持模型的文本能力,预训练时也混合了纯文本数据。各数据集大小统计如下表所示。
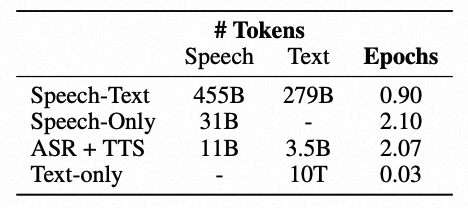
从GLM-4-9B-Base 初始化GLM-4-Voice,并扩展词汇表以包括语音 token(扩展细节见上文 LLM Tokenizaion部分)。预训练执行了 1 T个 token,其中固定采样比例为30%的文本数据,每个 epoch 包含完整的 Unsupervised speech data 和完整的Supervised speech-text data,其余由 Interleaved speech-text data 组成。
Supervised Fine-tuning
为创建一个类人化的语音 chatbot,使用了如下两类数据:
-
多轮对话式语音对话:主要来自基于文本的数据,排除了代码、数学相关内容,以专注适合语音交互的对话材料。
-
语音风格控制的口语对话:包含针对特定语音风格要求(例如速度、情感或方言)的优质多轮语音对话。
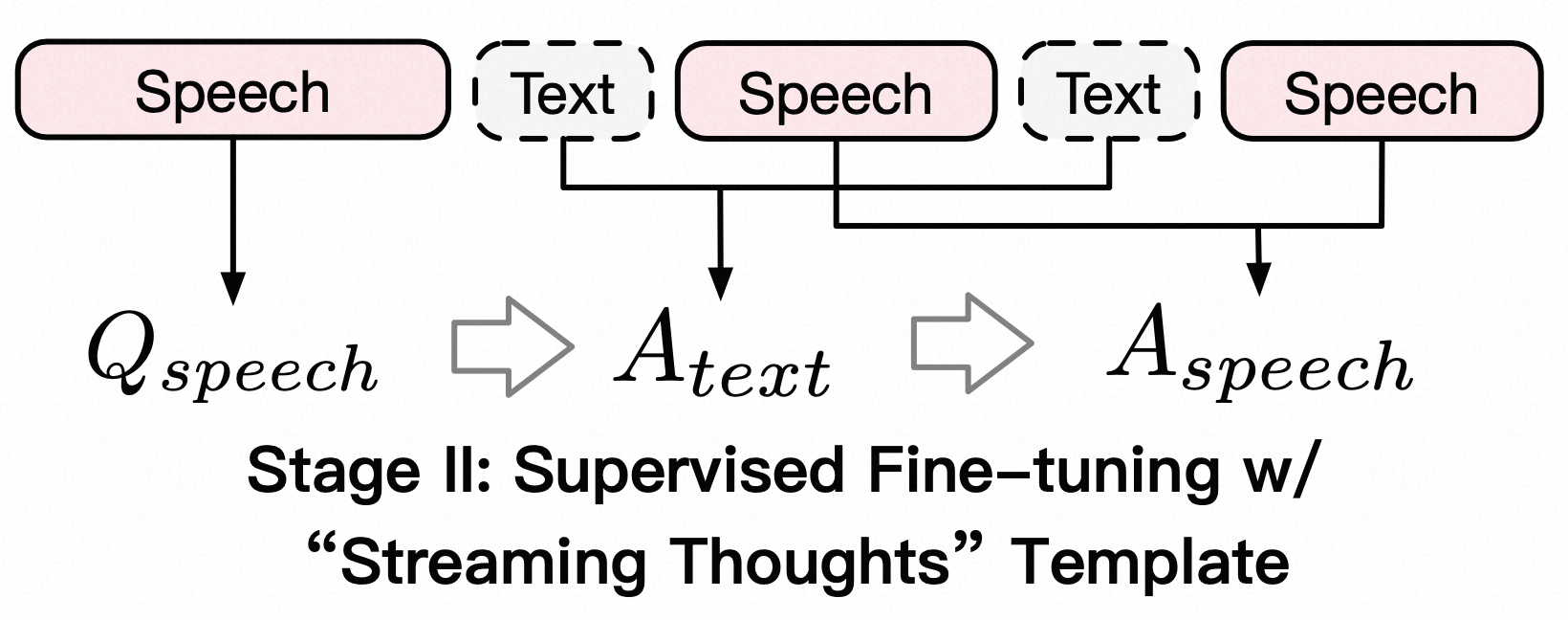
训练时,将语音到语音任务解耦为两个子任务:
- speech-to-text:基于用户的语音输入 Qs,模型输出文本 At
- speech-and-text-to-text:基于用户语音输入 Qs 和刚生成的 At,生成语音 As
GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令要求做出相应的声音变化,在最大程度保留语言模型智商的情况下仍然具有端到端建模的能力,同时具备低延迟性,最低只需10-20 个 token 即可合成语音。
效果评估
以下评估结果均引自原始Paper。个人对官方发布模型也做了部署测试,但由于模型不大,能力自然有限,各种问题错误也在预期之内,而且该项工作本也不是面向工业级应用,作者团队能把模型开源出来让大家学习已是很大贡献,所以这里不再较真个人测试结果。
Base Model Evaluation
对预训练模型的评估,主要通过两个任务:speech language modeling 和 spoken question answering。每个任务都有两种设置:从speech context 到 speech generation(即 S—>S),从speech context 到 text generation(即 S—>T)。实验结果如下。
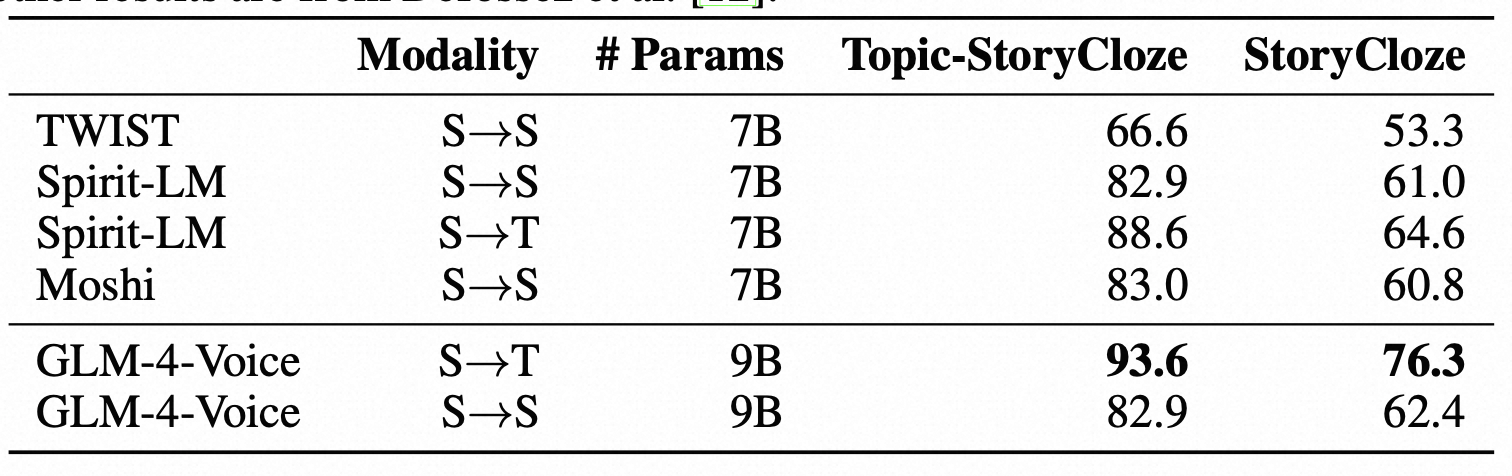
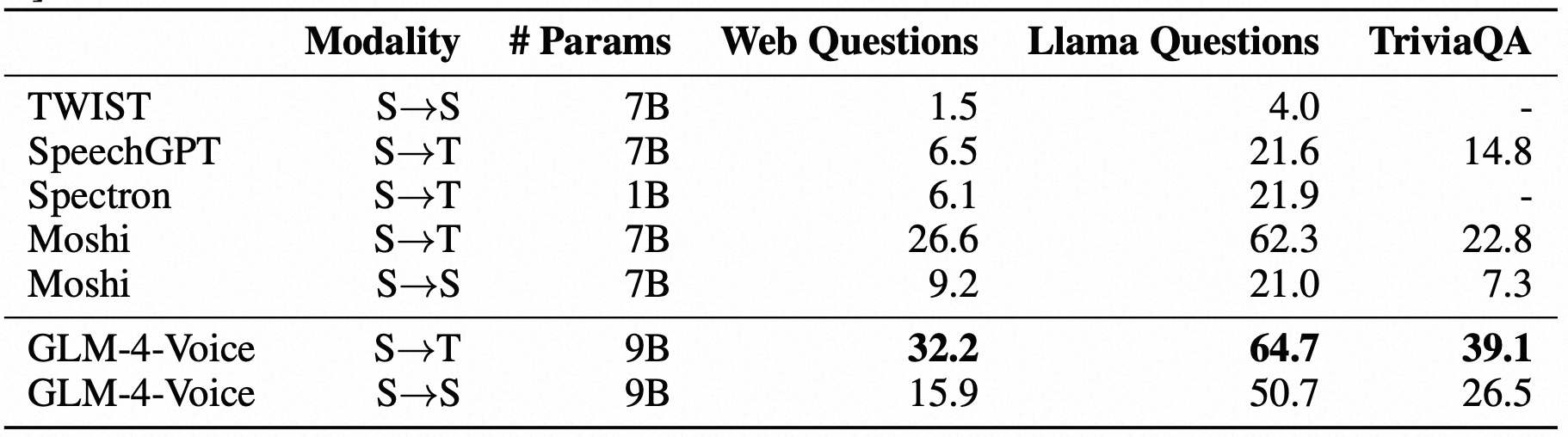
ASR / TTS 实验显示预训练模型拥有跟 whisper-large-v3 和 CosyVoice 相似的 ASR 和 TTS 能力。
Chat Model Evaluation
对于微调模型的评估,做了如下三项评估:
-
ChatGPT Score:主要评估模型的问答能力和知识记忆能力,实验中使用了 GPT-4o 评估模型响应的质量和正确性。
-
Speech Quality:使用 UTMOS 综合评估语音质量,语音质量包括自然度、清晰度、流畅度等多个维度,这些维度共同构成了人们对语音整体质量的感知。
-
Speech-Text Alignment:主要评估生成文本和生成语音的相关性,评估时把语音通过 whipser-large-v3 转成了文本。
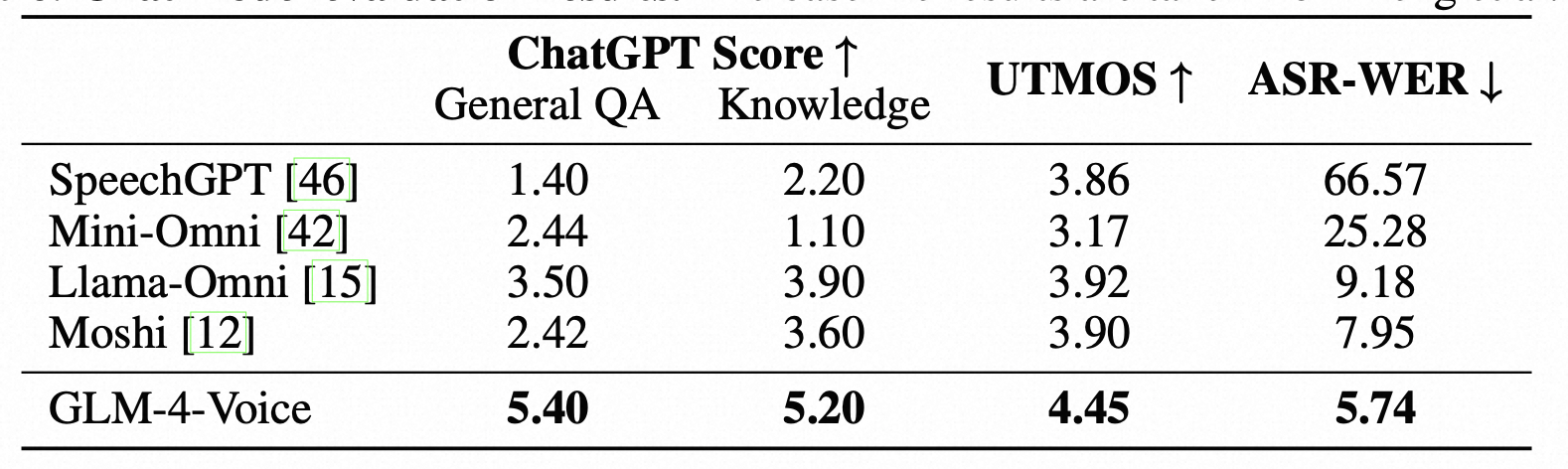
总结
本文着重讲述了 GLM-4-Voice 从语音输入到语音回复的详细处理过程,其中 Speech Tokenization 和 Speech Decoder 两个环节是没处理过语音模态的同学所比较陌生的,这两块对于高质量的语音理解和生成至关重要,目前已有比较多的研究。GLM-4-Voice 采用的音频离散化和音频合成方案有一定代表性,后续的其它语音端到端模型很多也采用了同样方案。另外 GLM-4-Voice 所采用的流式思考架构,允许语音输入与文本、语音输出交替进行,一方面降低响应延迟,提升了交互实时性,另一方面也提升了音频输出质量,对后续研究很有参考意义。从业务应用角度看,GLM-4-Voice 还是更偏学术价值的作品,其在复杂指令遵循、复杂语音环境理解、双工通话等方面仍有很大提升空间,期待后续会有跟 LLM 领域一样强大的工业应用级作品出现。
参考资料
- Github: GLM-4-Voice
- GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
- CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
- Matcha-TTS: A fast TTS architecture with conditional flow matching