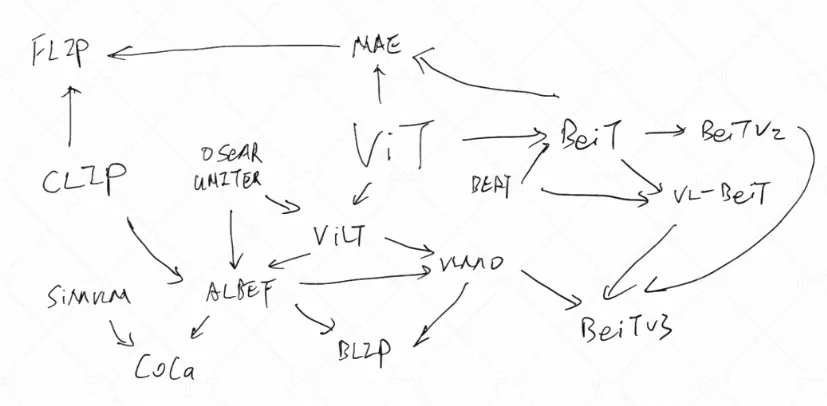
多模态模型图谱
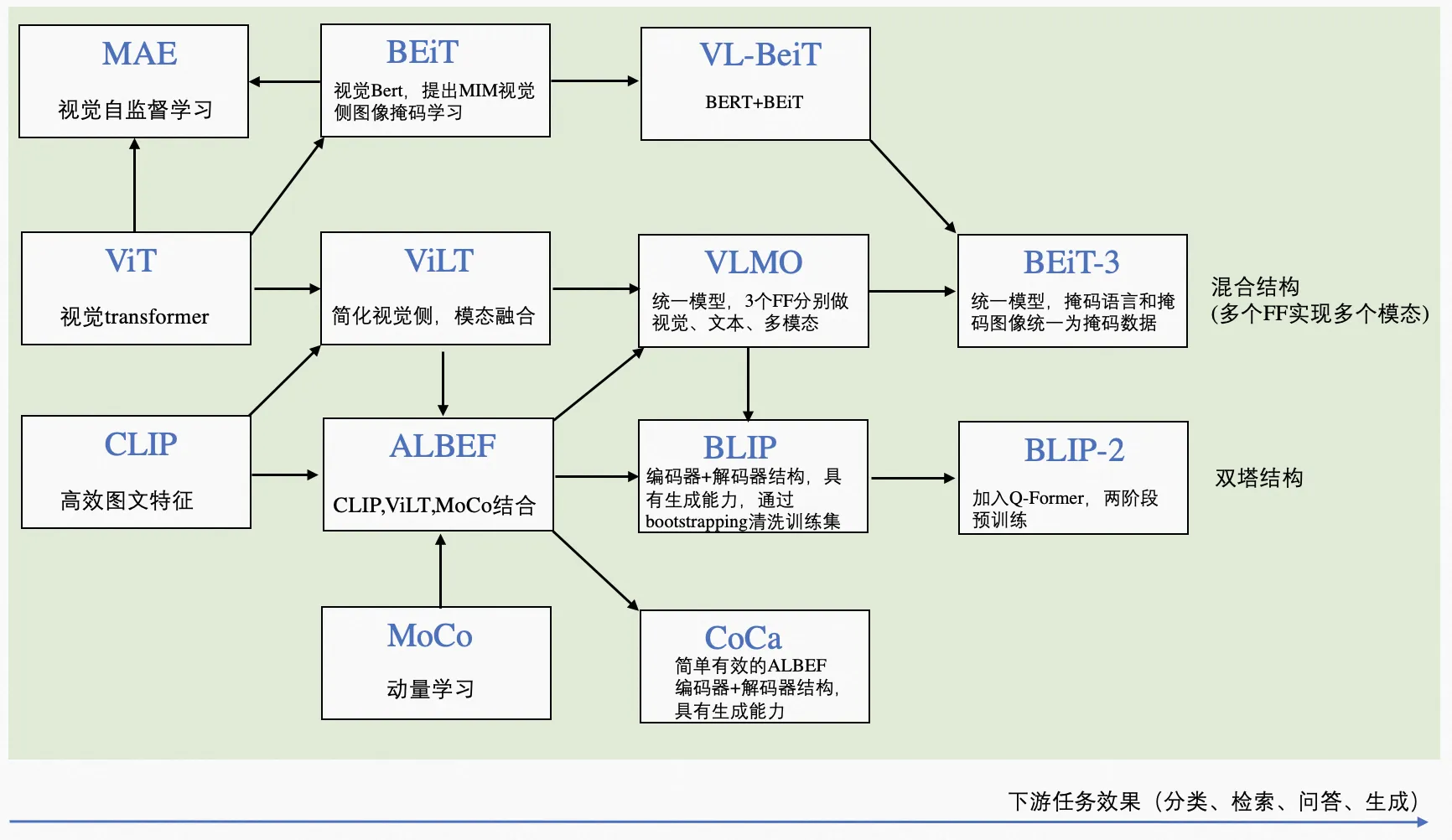
多模态论文一览
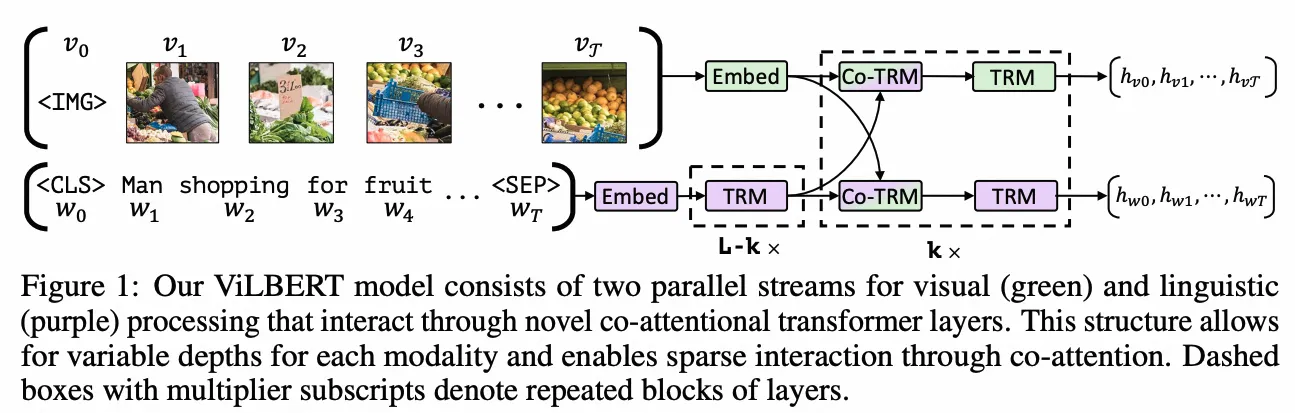
ViLBERT
- Paper:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- 作者:Jiasen Lu 等,Georgia Institute of Technology, 2Facebook AI Research, 3Oregon State University
- 时间:2019.8.6
- 架构图:
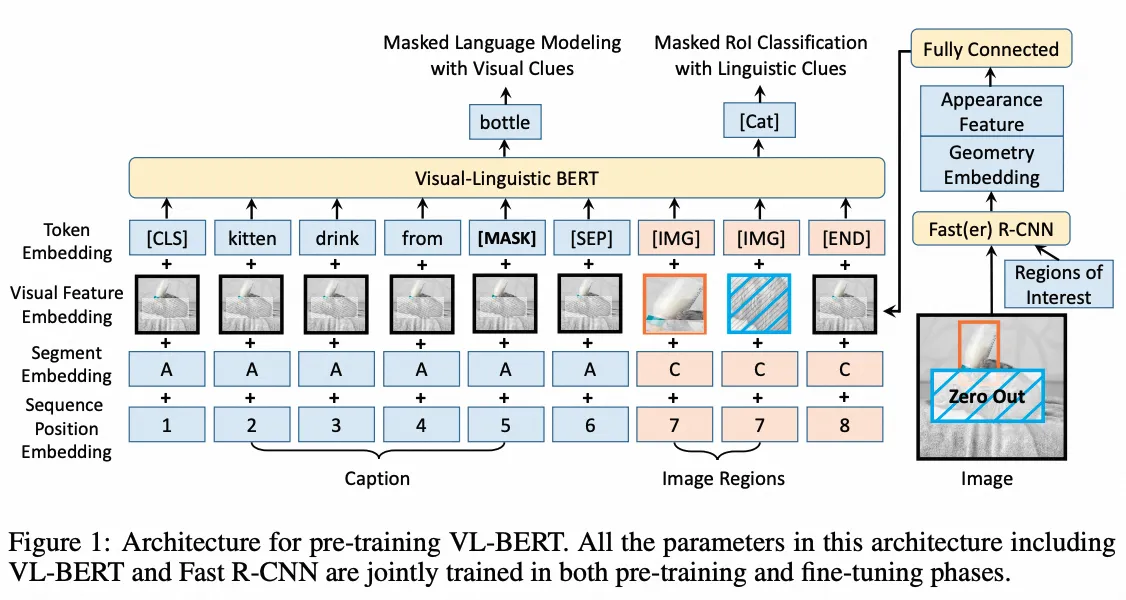
VL-BERT
- paper:VL-BERT: Pre-training of Generic Visual-Linguistic Representations
- 作者:Weijie Su 等,中科大 & 微软亚研院
- 时间:2020.2.18
- 架构图:
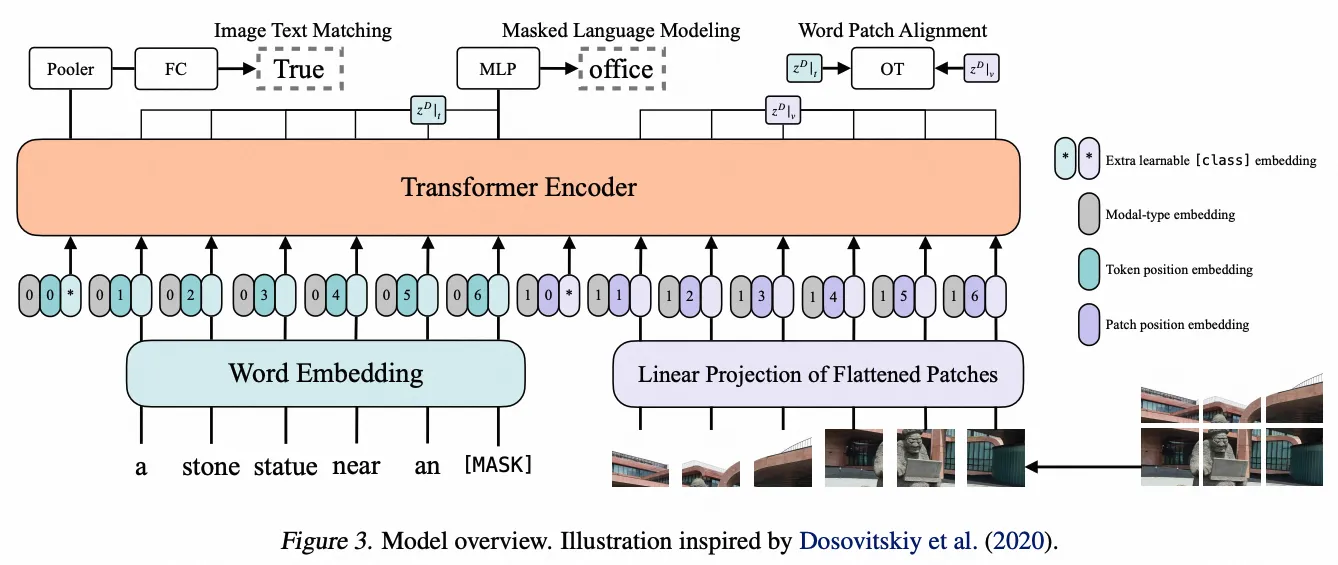
ViLT
- paper:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 作者:Wonjae Kim
- 时间:2021.6.10
- 架构图:
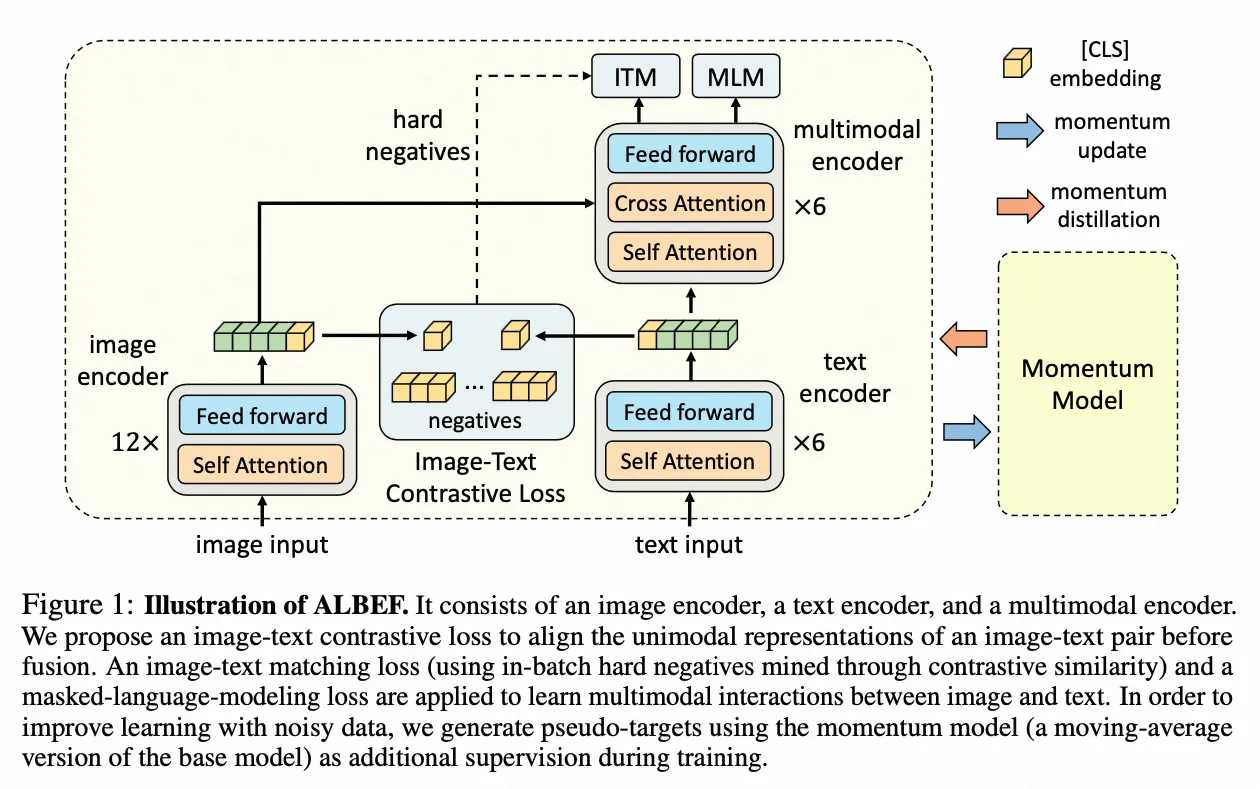
ALBEF
- paper:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- 作者:JunnanLi 等,Salesforce Research
- 时间:2021.10.7
- 架构图:
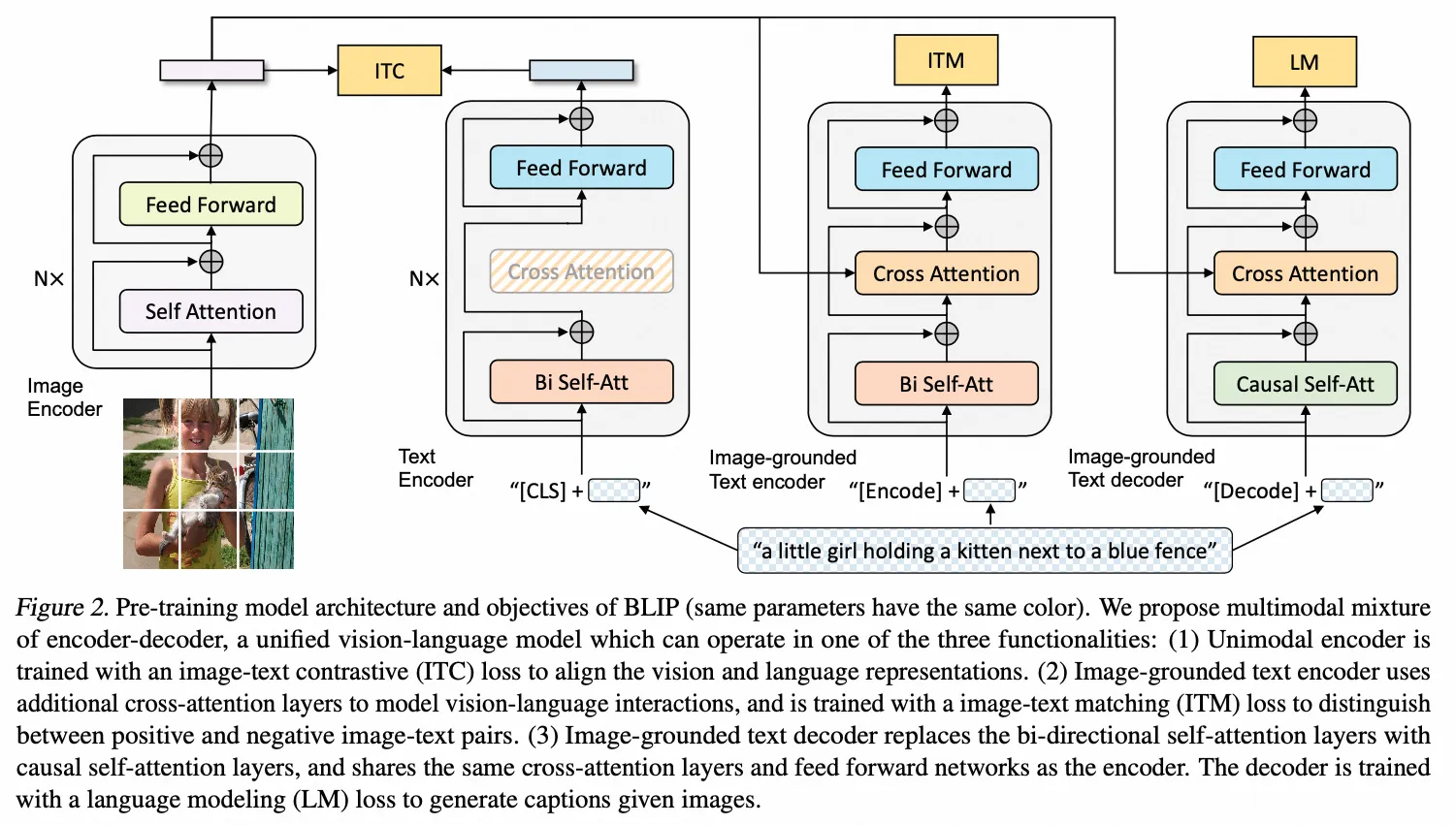
BLIP
- paper:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 作者:JunnanLi 等,Salesforce Research
- 时间:2022.2.15
- 架构图:
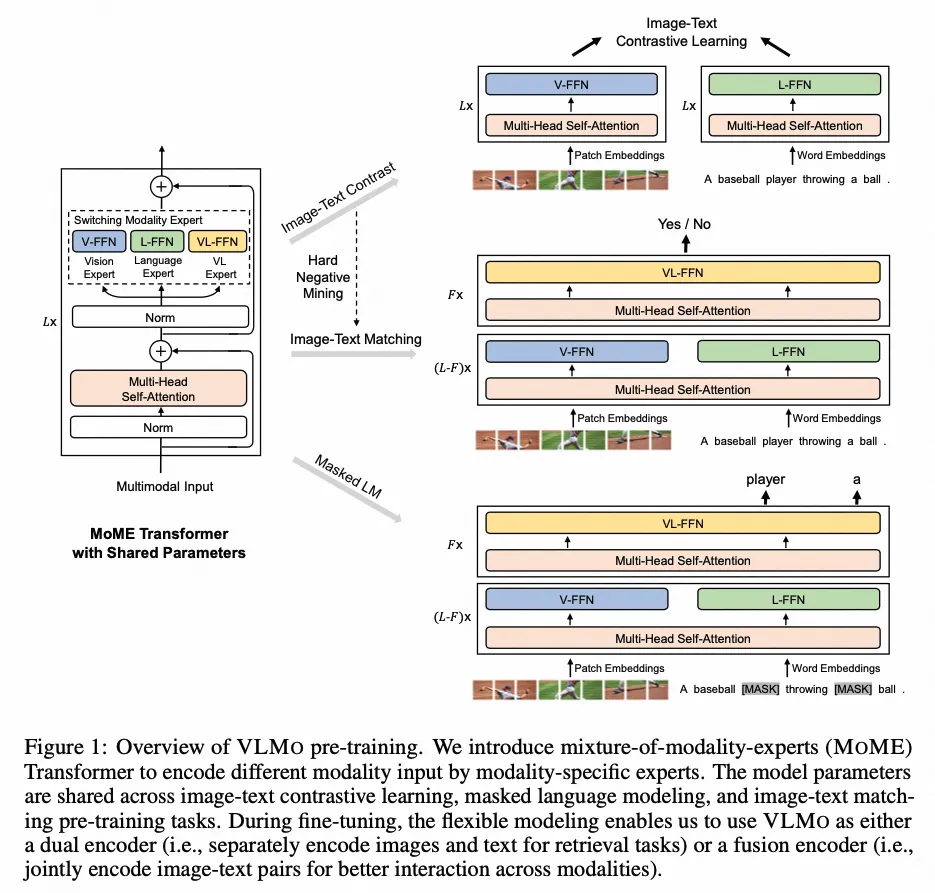
VLMO
- paper:VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
- 作者:Hangbo Bao 等,微软
- 时间:2022.3.27
- 架构图:
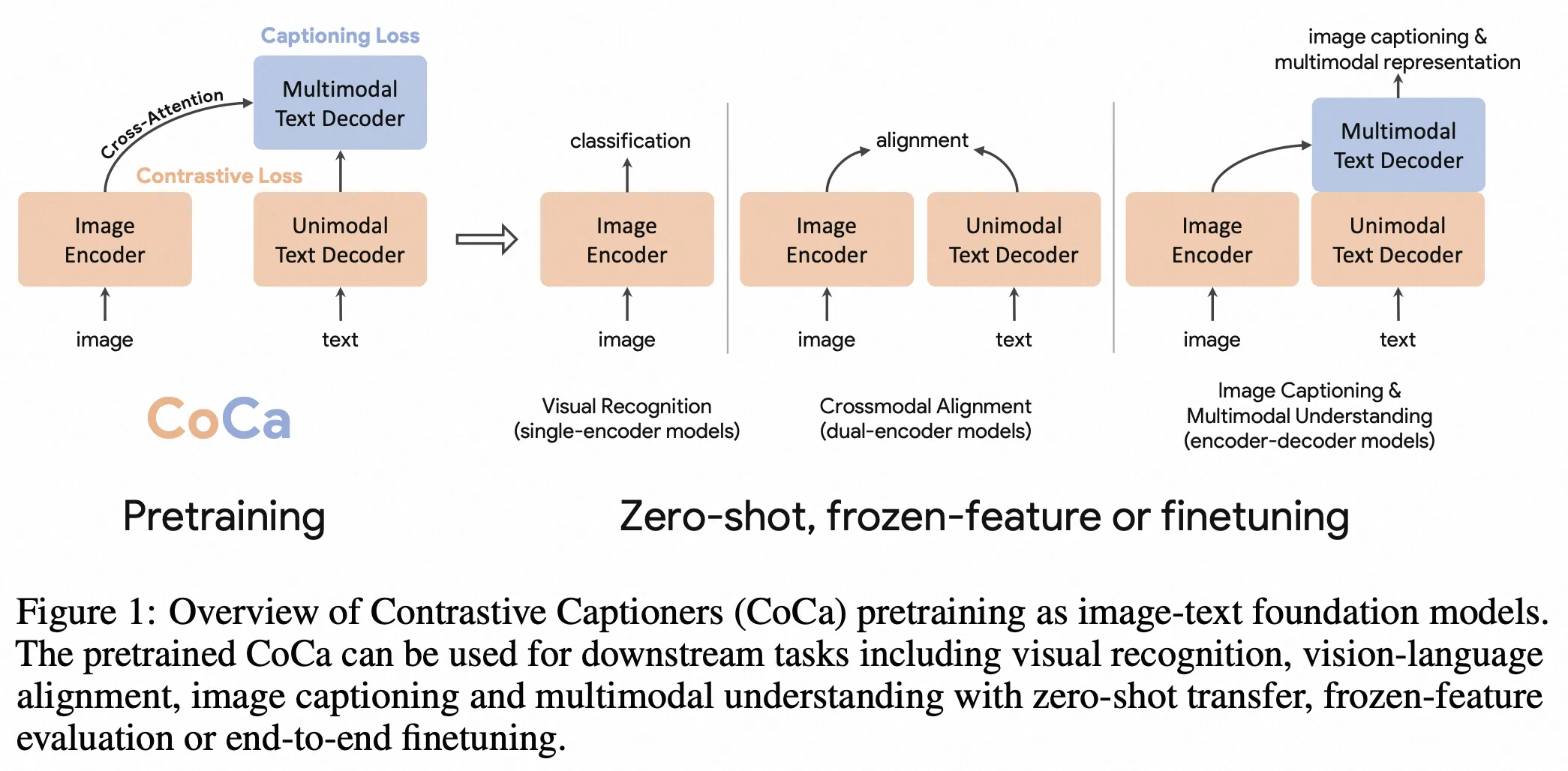
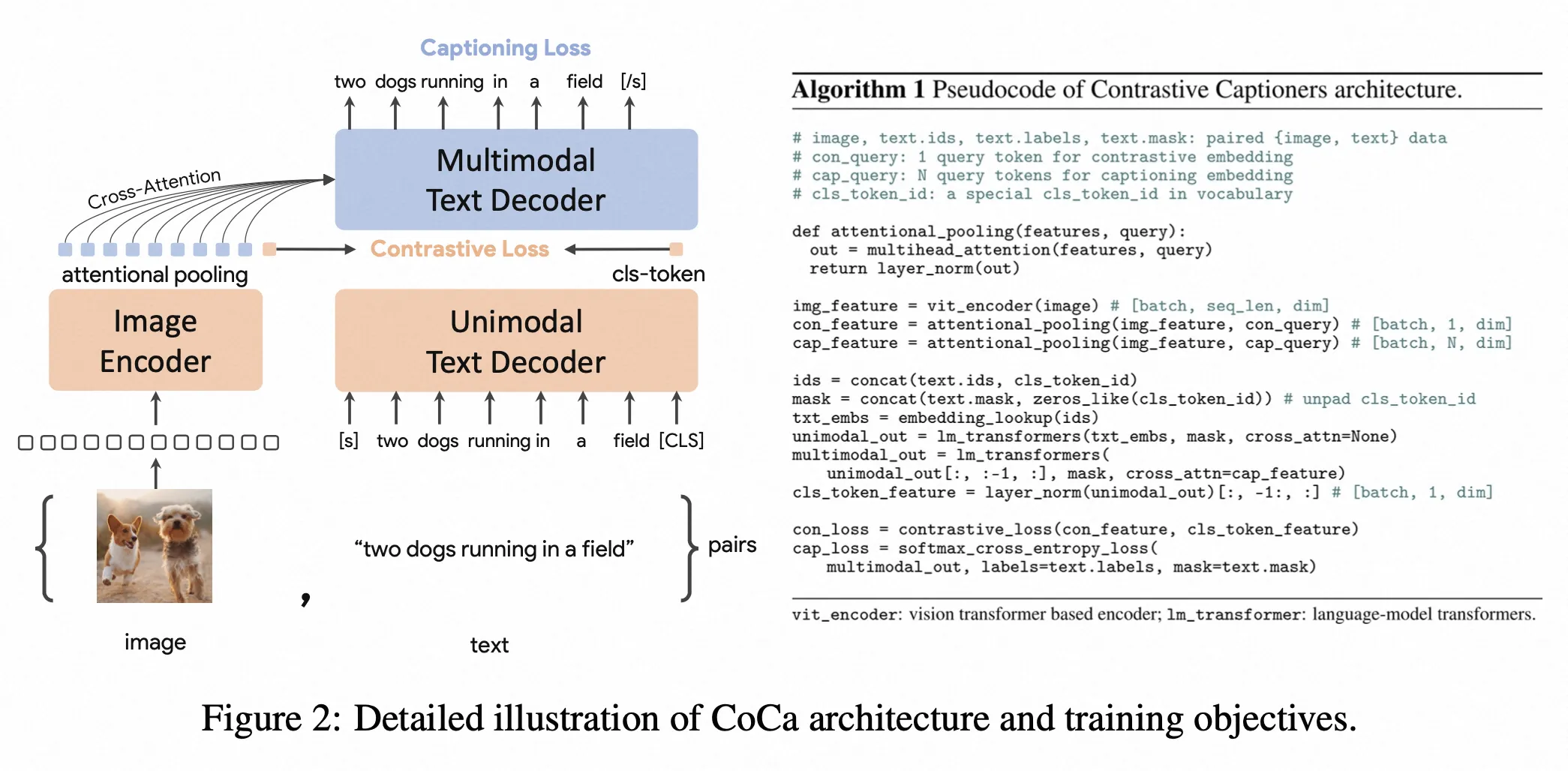
CoCa
- paper:CoCa: Contrastive Captioners are Image-Text Foundation Models
- 作者:Jiahui Yu 等,Google
- 时间:2022.6.14
- 架构图:
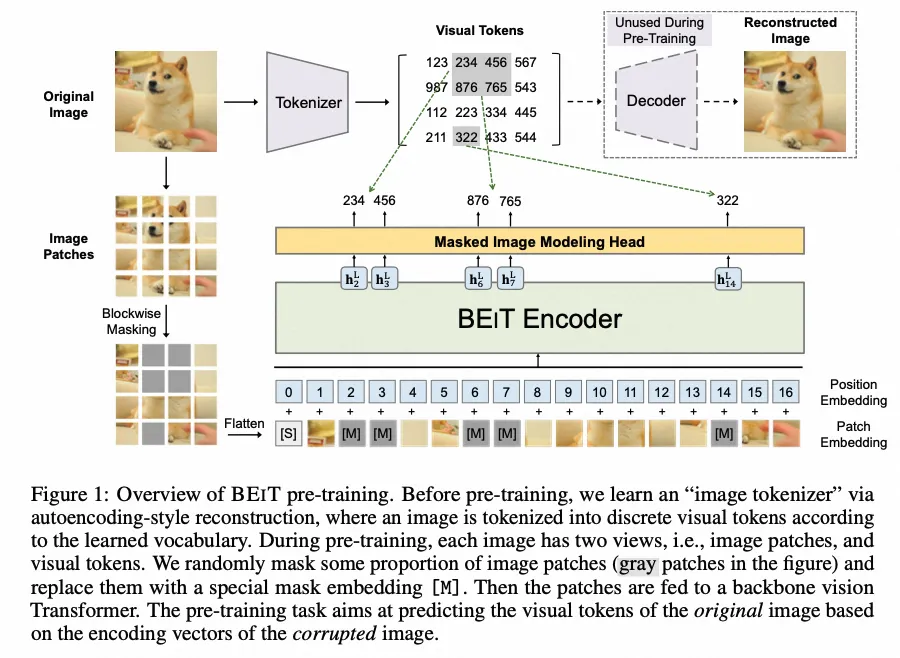
BeiT
- paper:BEiT: BERT Pre-Training of Image Transformers
- 作者:Hangbo Bao 等,哈工大,微软
- 时间:2022.9.3
- 架构图:纯视觉模型,非多模态
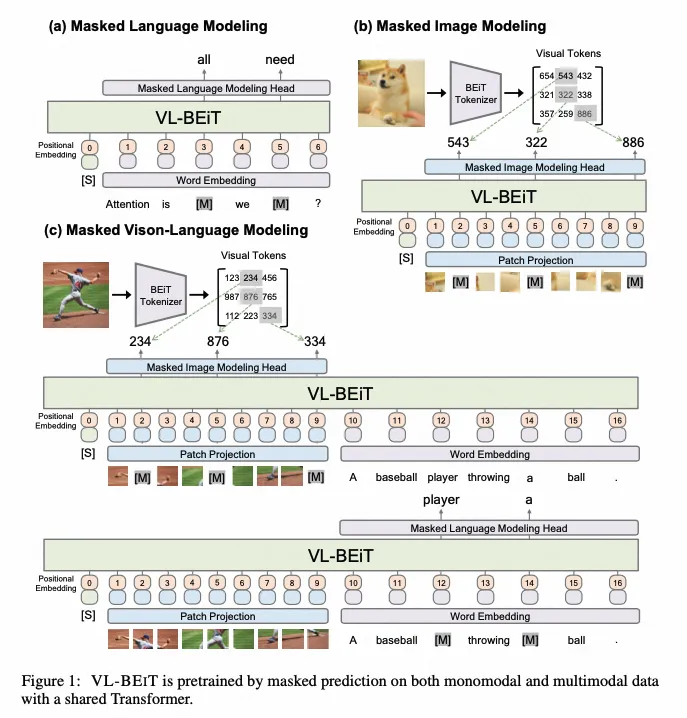
VL-BeiT
- paper:VL-BEIT: Generative Vision-Language Pretraining
- 作者:Hangbo Bao 等,微软
- 时间:2022.9.3
- 架构图:
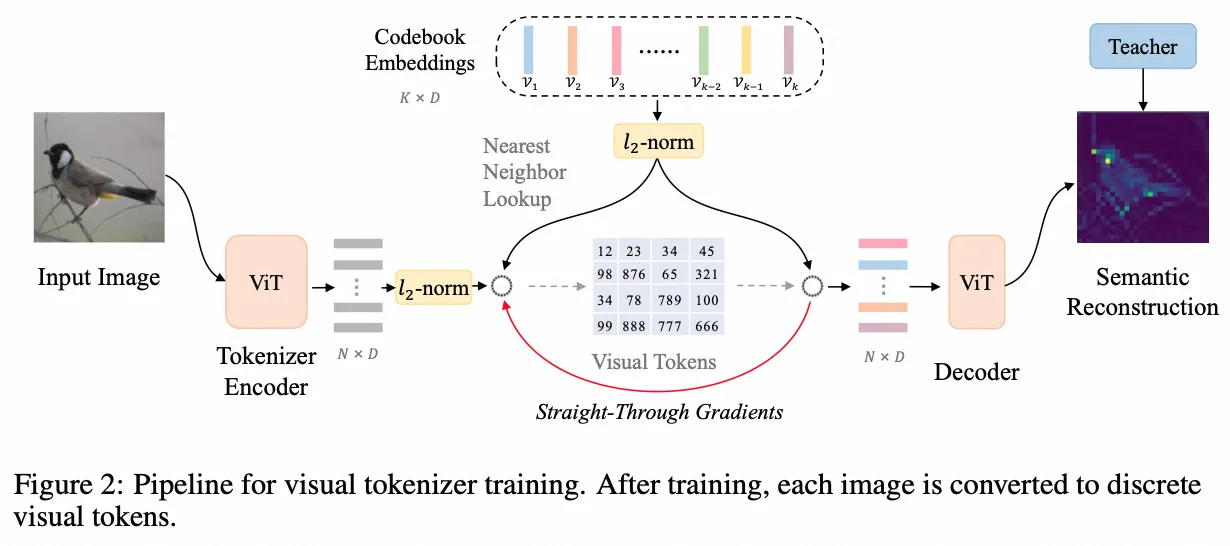
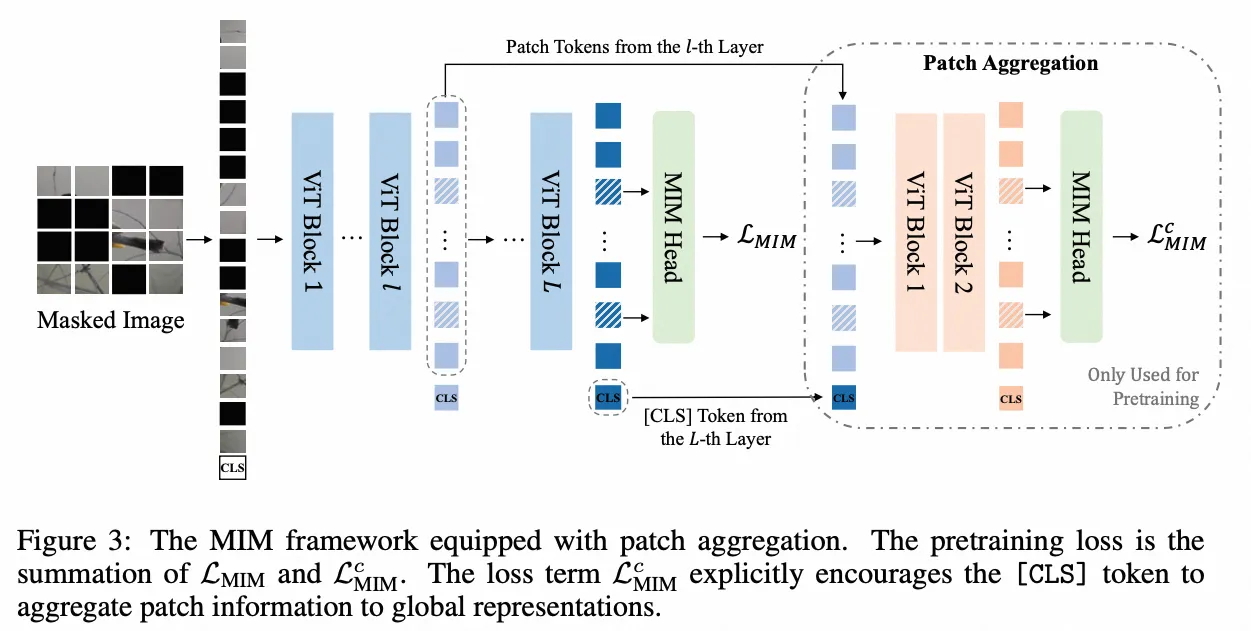
BeiTv2
- paper:BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
- 作者:Zhiliang Peng 等,中科院大学,微软
- 时间:2022.10.3
- 架构图:纯视觉模型,非多模态
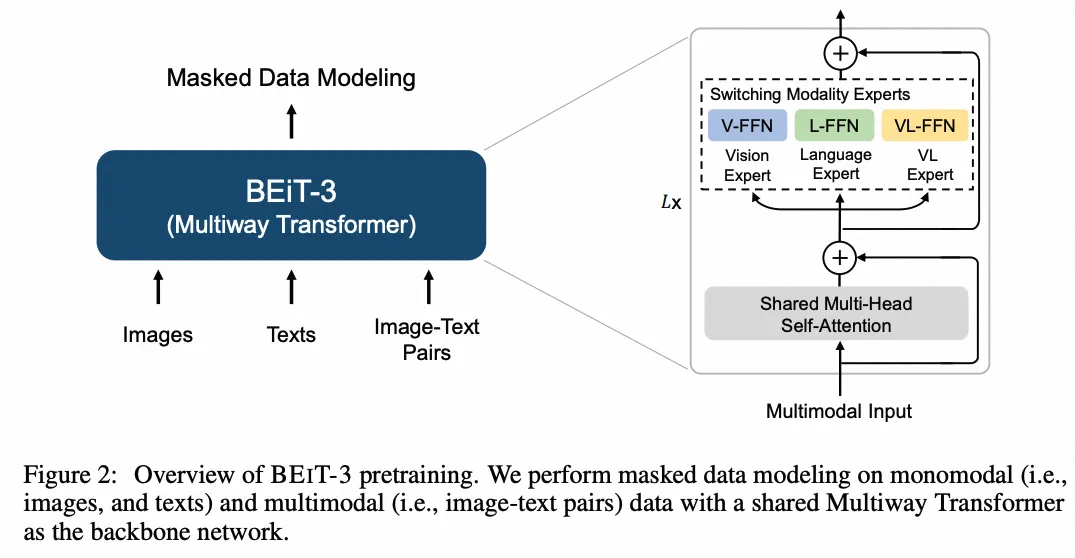
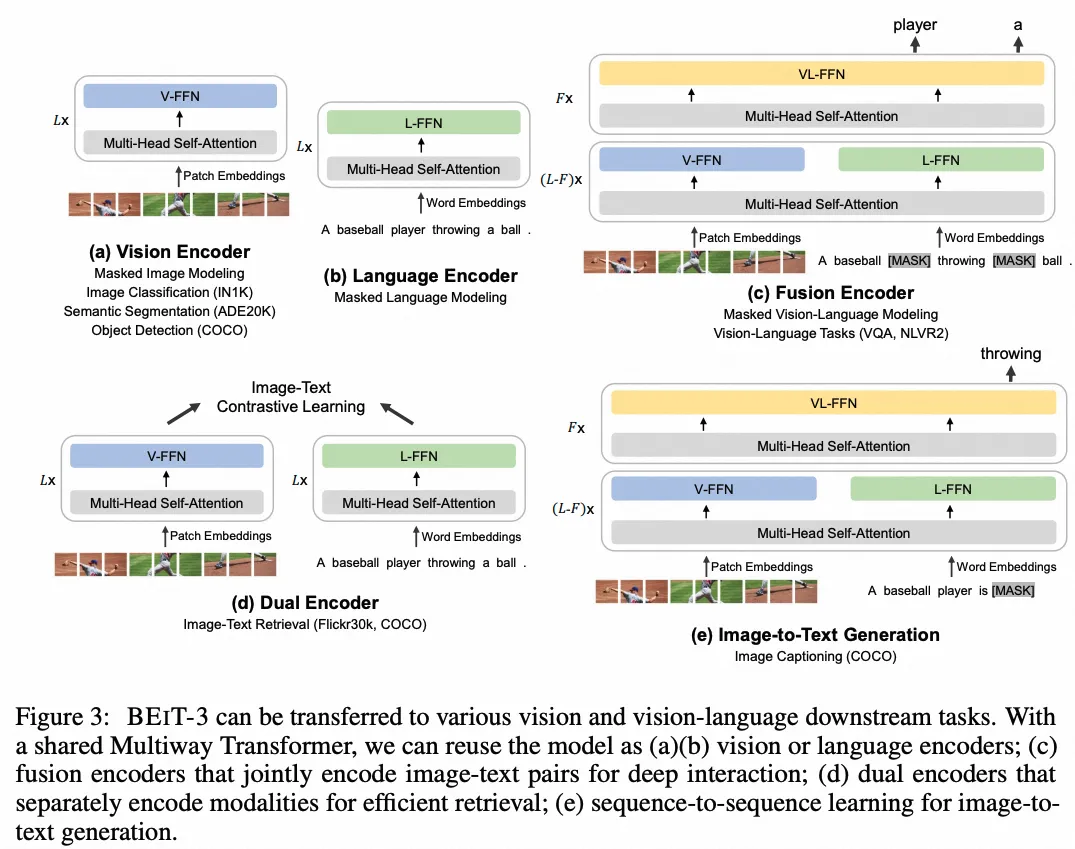
BeiTv3
- paper:Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
- 作者:Wenhui Wang 等,微软
- 时间:2022.8.31
- 架构图:
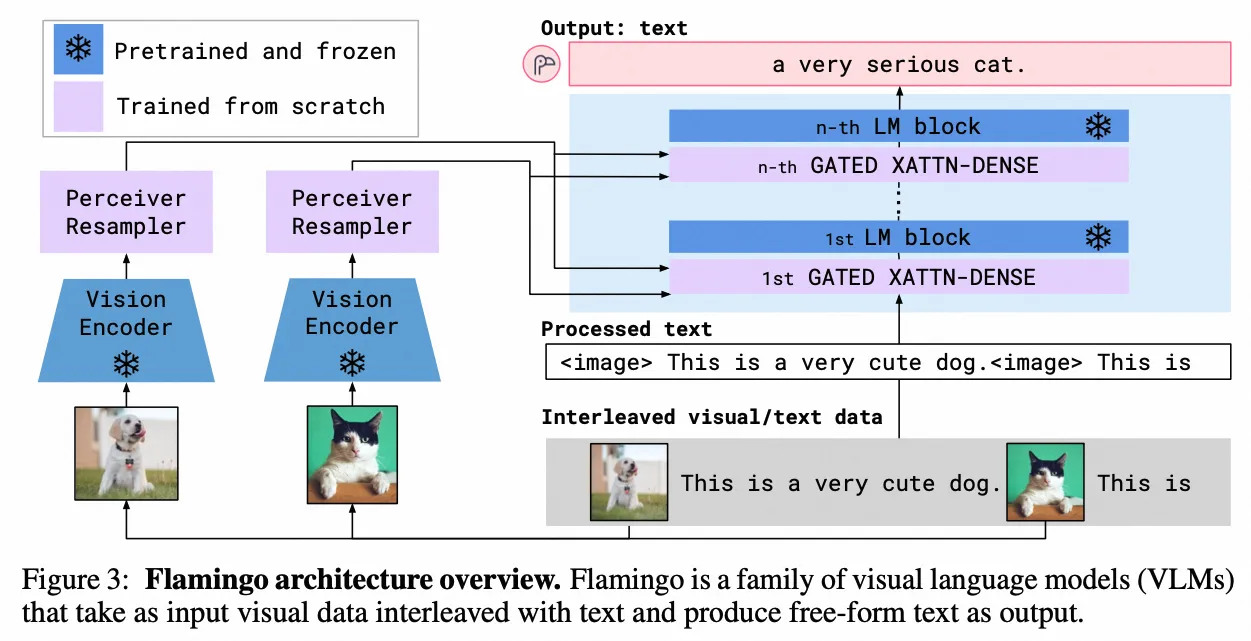
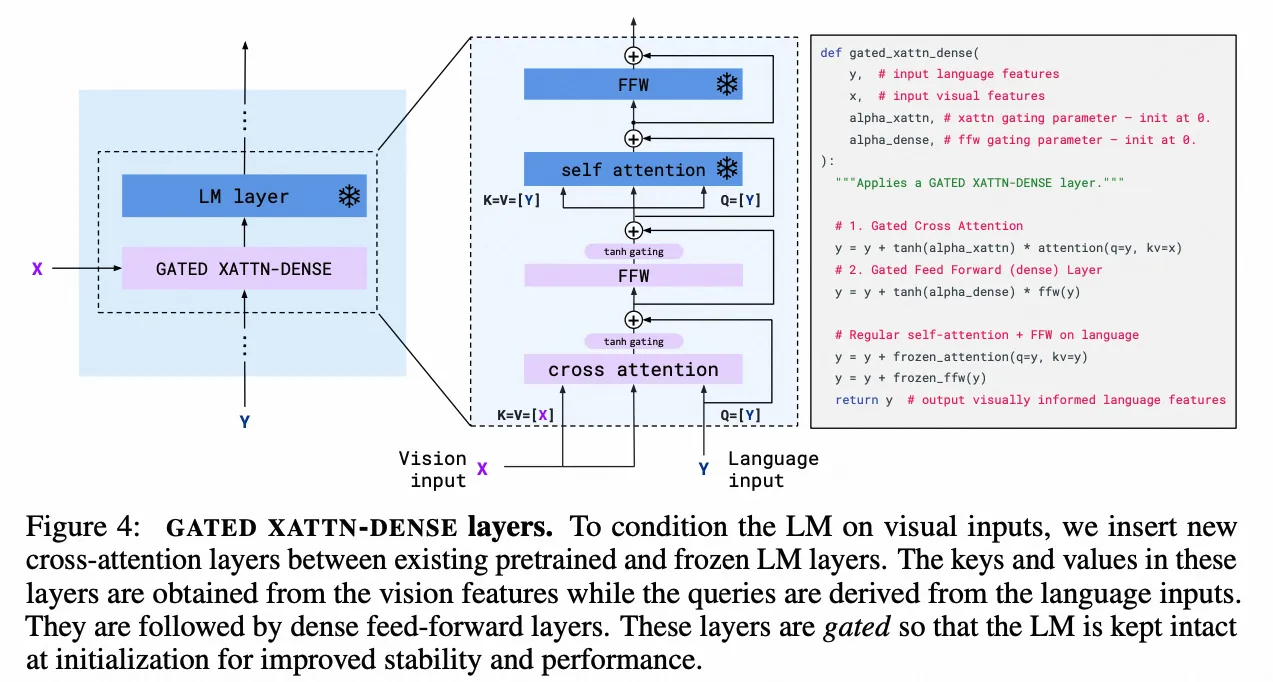
Flamingo
- Paper:Flamingo: a Visual Language Model for Few-Shot Learning
- 作者:Jean-Baptiste Alayrac 等,DeepMind
- 时间:2022.11.15
- 架构图:
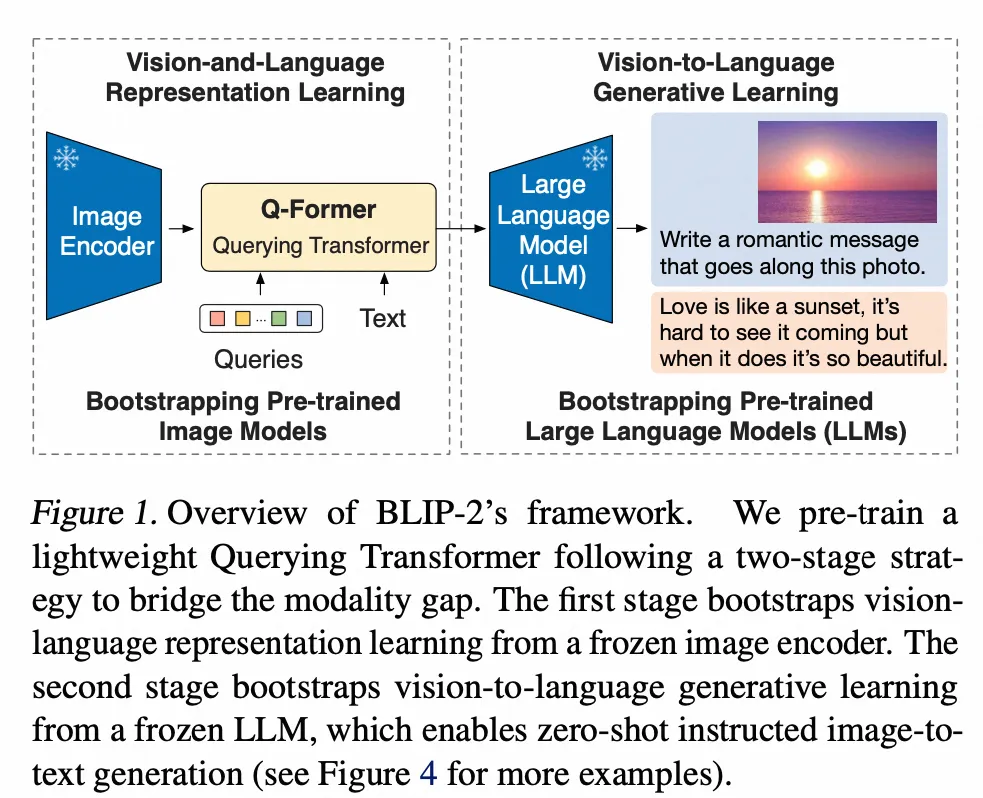
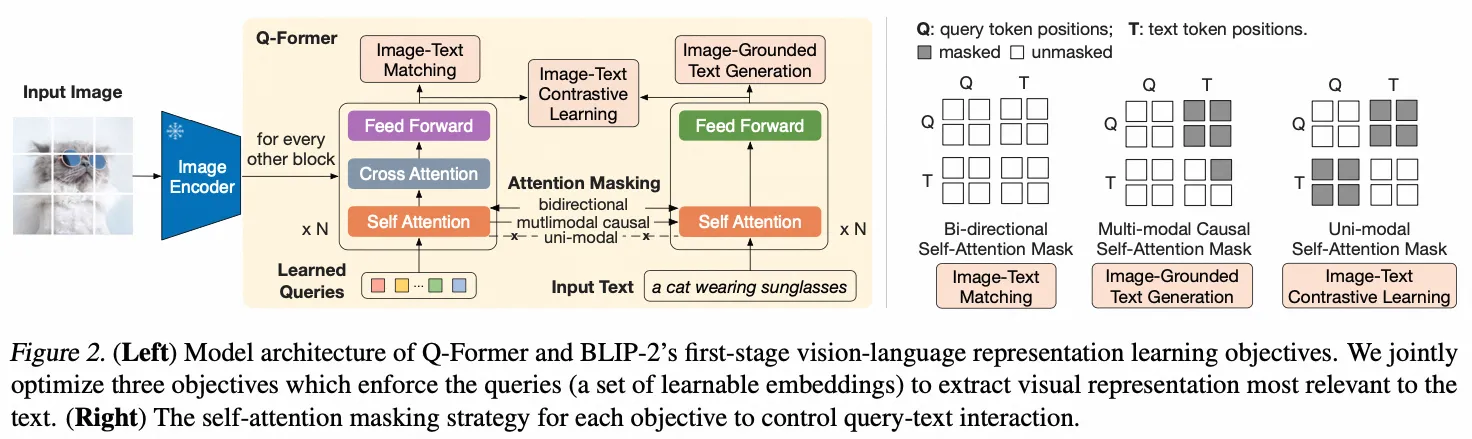
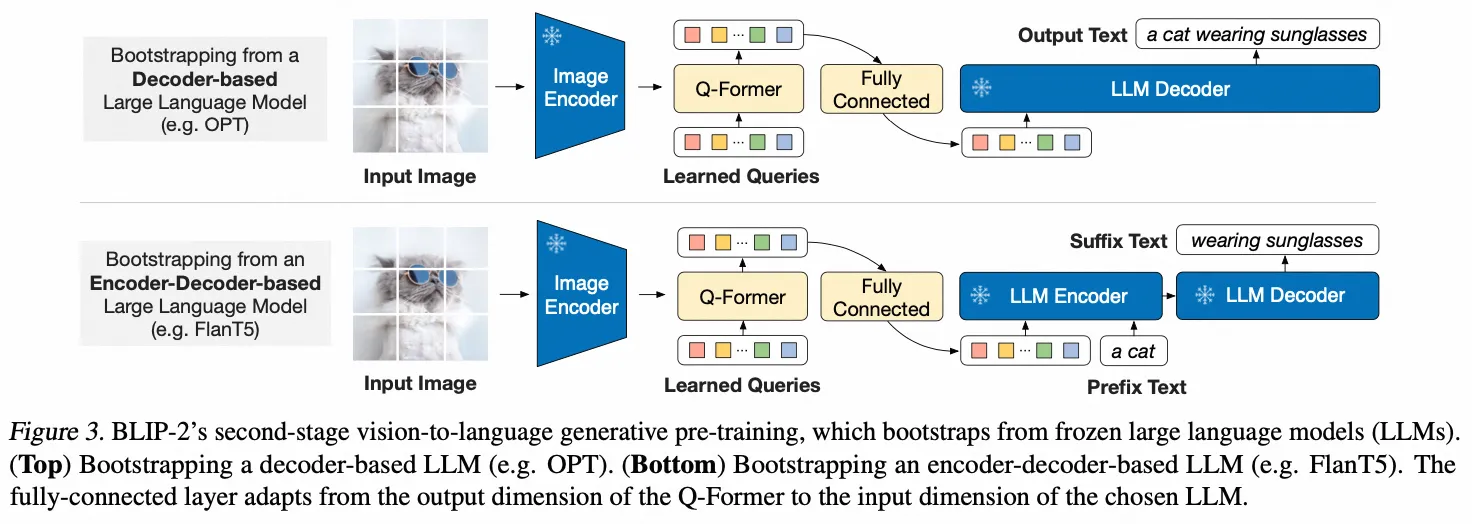
BLIP2
- Paper:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 作者:JunnanLi 等,Salesforce Research
- 时间:2023.1.15
- 架构图:
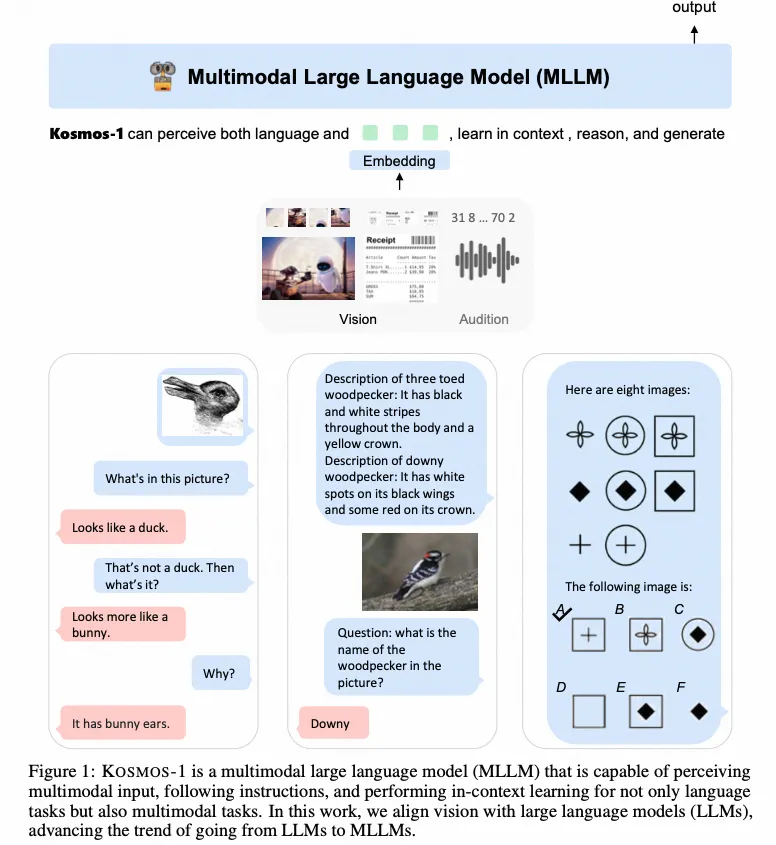
Kosmos-1
- Paper:Language Is Not All You Need: Aligning Perception with Language Models
- 作者:Shaohan Huang 等,Microsoft
- 时间:2023.3.1
- 原理:一图胜千言,第一张图就把最重要的idea说了。就是把其他模态的信息,都可以变成Embedding,然后输入到语言模型作为中间的context,然后在和语言进行交互。 这其实也是GPT4最重要的关键。
- 架构图:
ImageBind
- Paper:ImageBind: One Embedding Space To Bind Them All
- 作者:Rohit Girdhar 等,Meta
- 时间:2023.3.31
- 架构图:

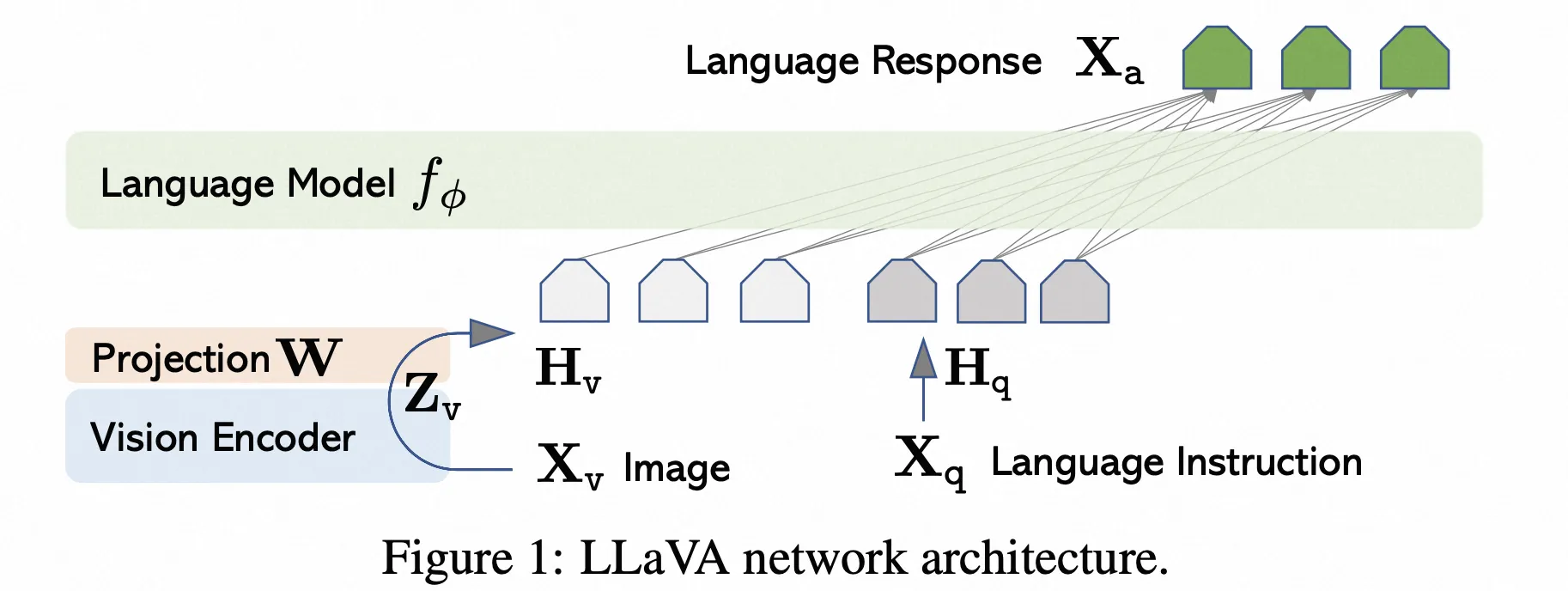
LLAVA
- Paper:Visual Instruction Tuning
- 作者:Haotian Liu 等,Microsoft 等
- 时间:2023.4.17
- 架构图:
MiniGPT-4
- Paper:MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
- 作者:Deyao Zhu 等,King Abdullah University of Science and Technology
- 时间:2023.4.20
-
架构图:
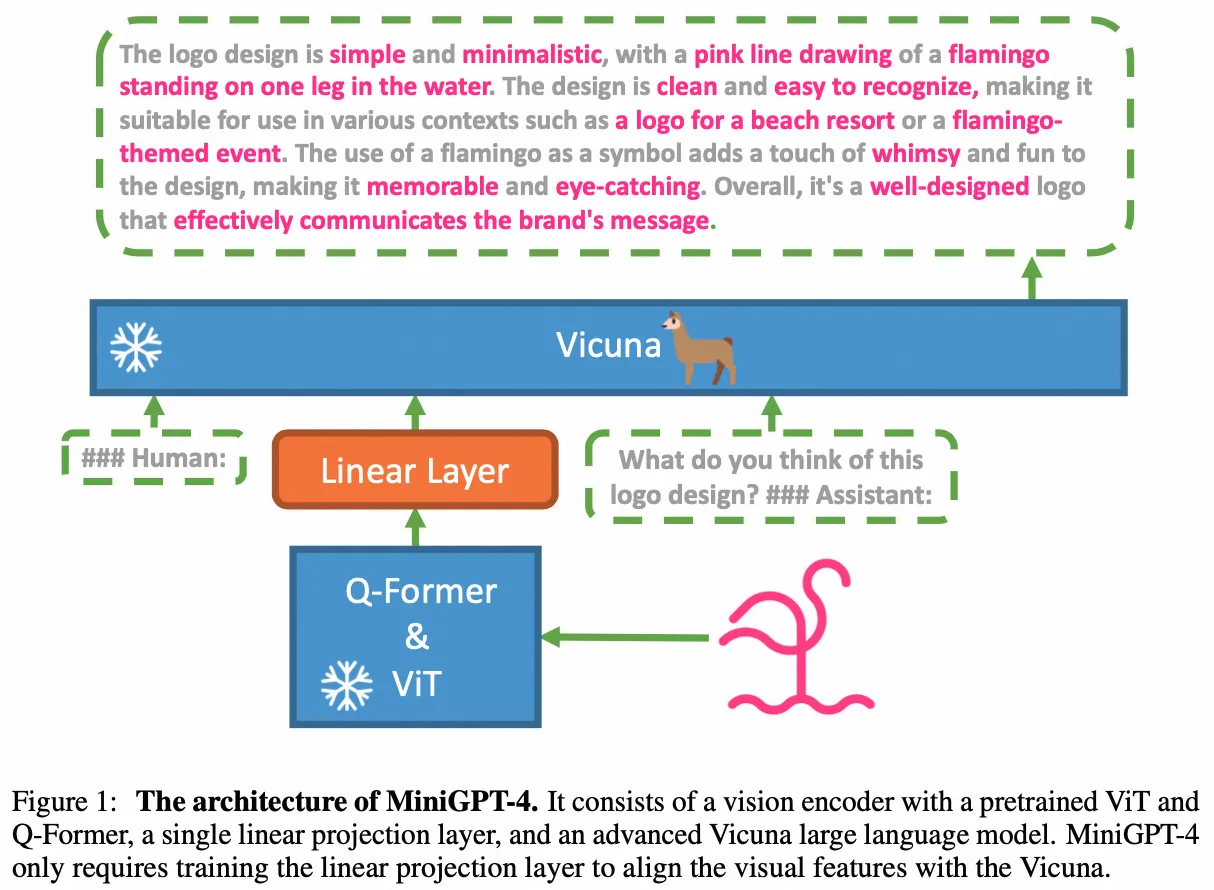
- 原理:MiniGPT-4 的模型架构遵循 BLIP-2,因此,训练 MiniGPT-4 分两个阶段。
第一个传统预训练阶段使用 4 张 A100 卡在 10 小时内使用大约 500 万个对齐的图像-文本对进行训练。 在第一阶段之后,Vicuna 虽然能够理解图像。 但是Vicuna的生成能力受到了很大的影响。
为了解决这个问题并提高可用性,MiniGPT-4 提出了一种通过模型本身和 ChatGPT 一起创建高质量图像文本对的新方法。 基于此,MiniGPT-4 随后创建了一个小规模(总共 3500 对)但高质量的数据集。
第二个微调阶段在对话模板中对该数据集进行训练,以显著提高其生成的可靠性和整体的可用性。 令人惊讶的是,这个阶段的计算效率很高,使用单个 A100 只需大约 7 分钟即可完成。
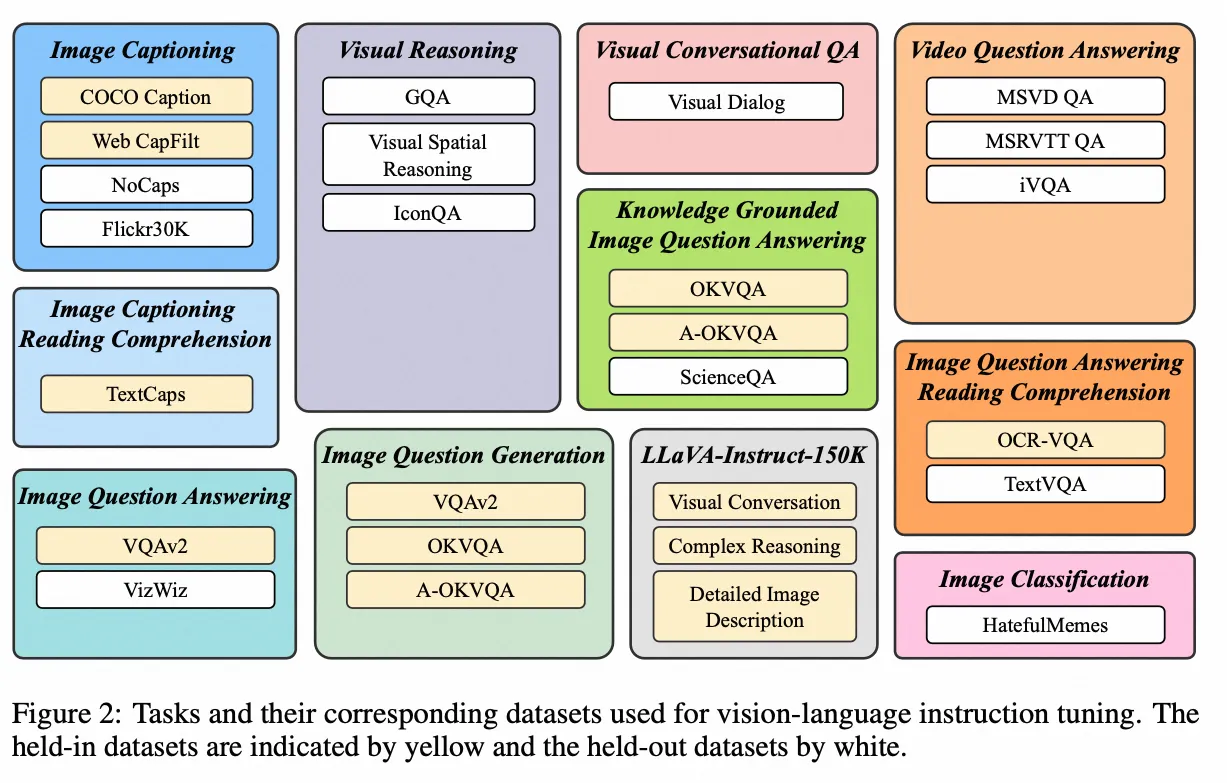
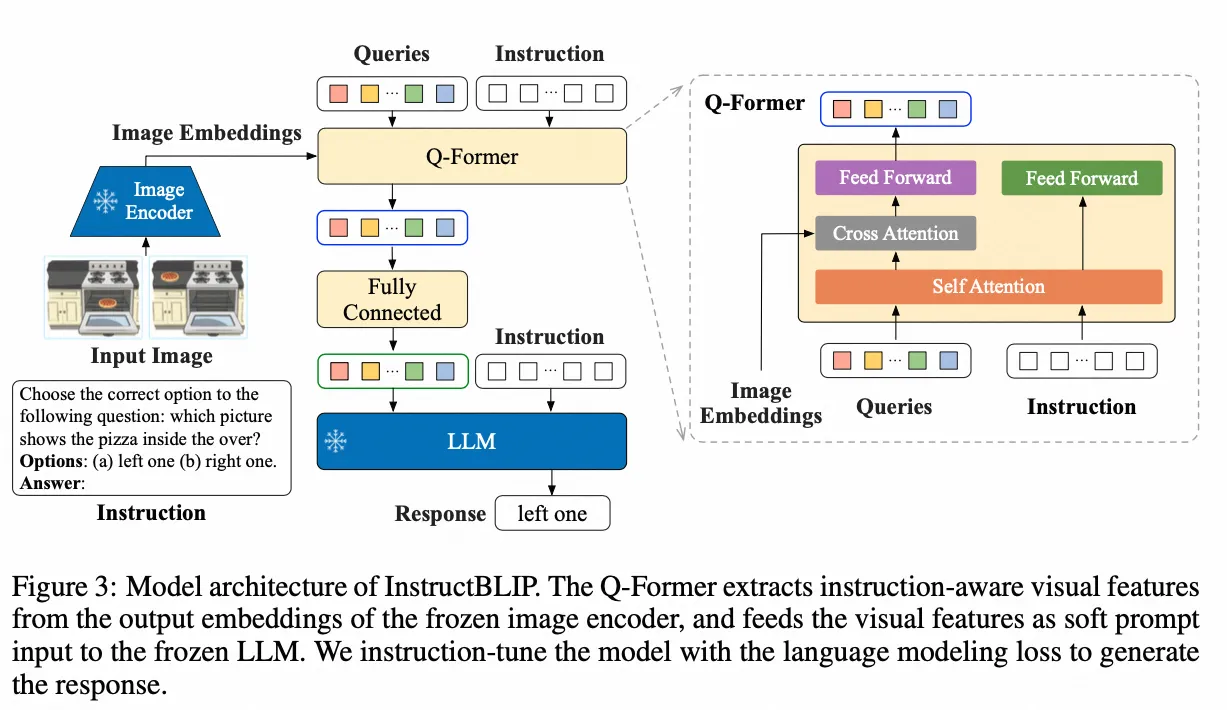
InstructBLIP
- Paper:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- 作者:Wenliang Dai 等,Salesforce Research 等
- 时间:2023.5.11
- 原理:InstructBLIP 是 BLIP 作者团队在多模态领域的又一续作。现代的大语言模型在无监督预训练之后会经过进一步的指令微调 (Instruction-Tuning) 过程,但是这种范式在视觉语言模型上面探索得还比较少。InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
- 架构图:
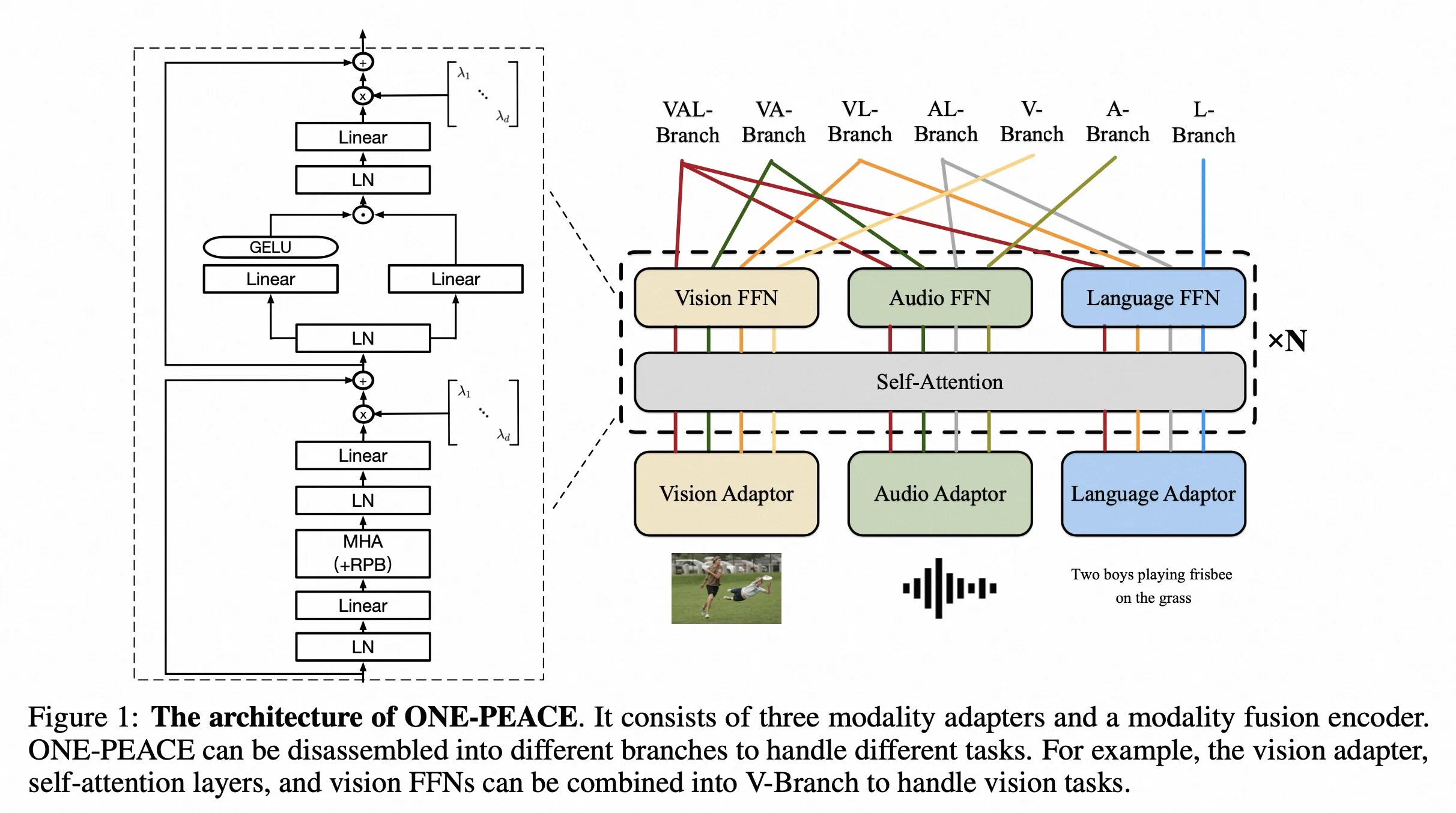
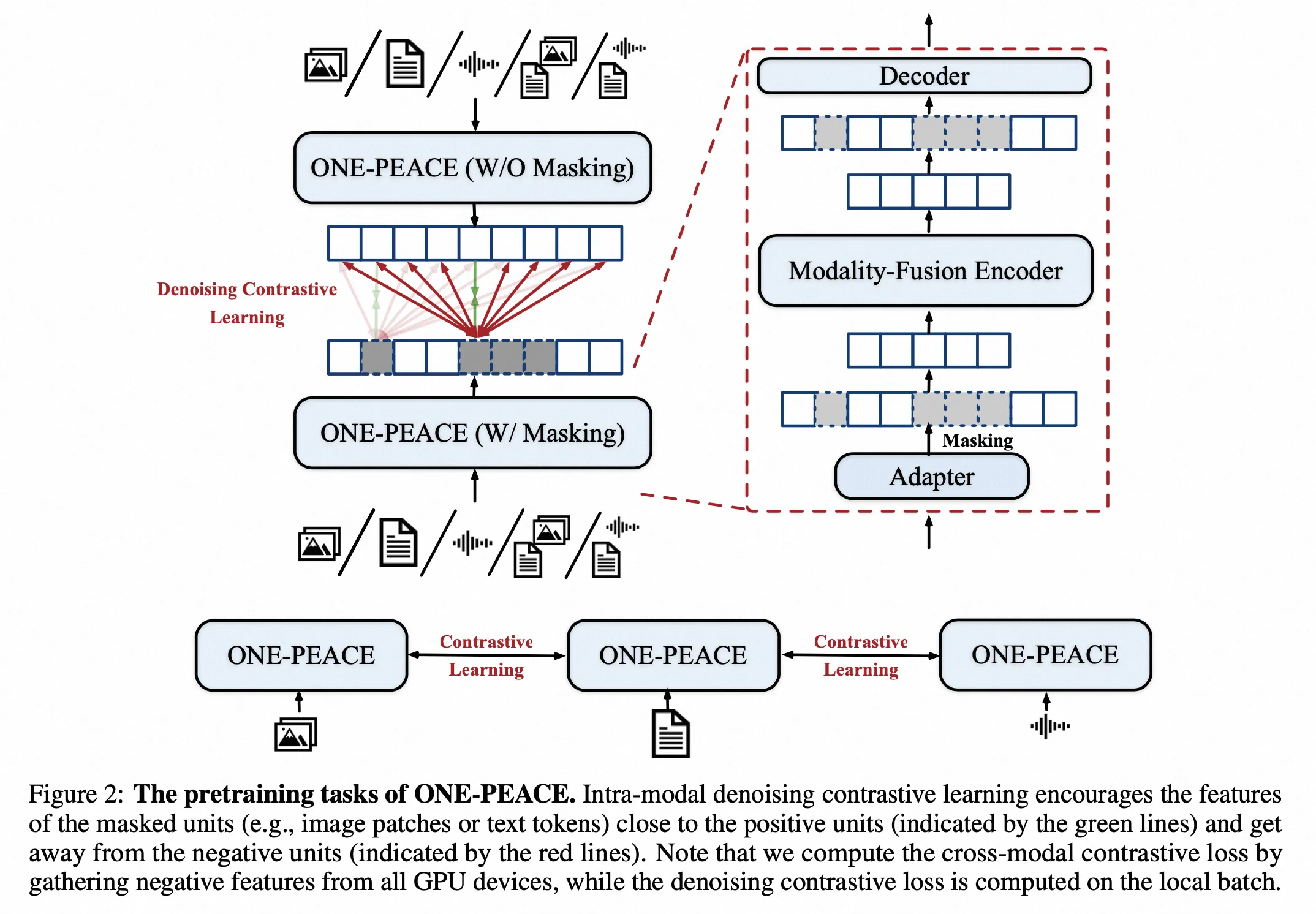
ONE-PEACE
- Paper:ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities
- 作者:Peng Wang 等,Alibaba
- 时间:2023.5.18
- 架构图:
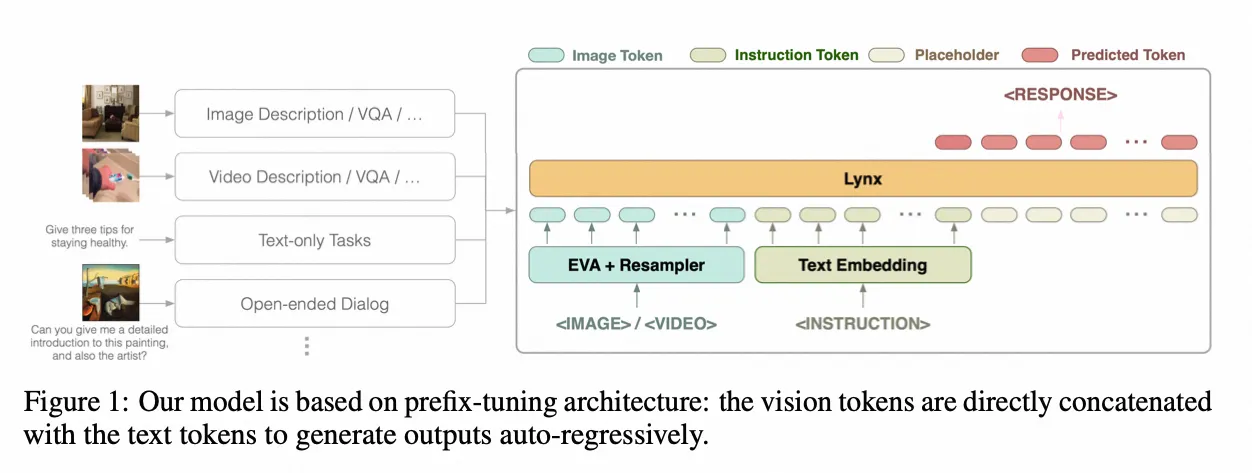
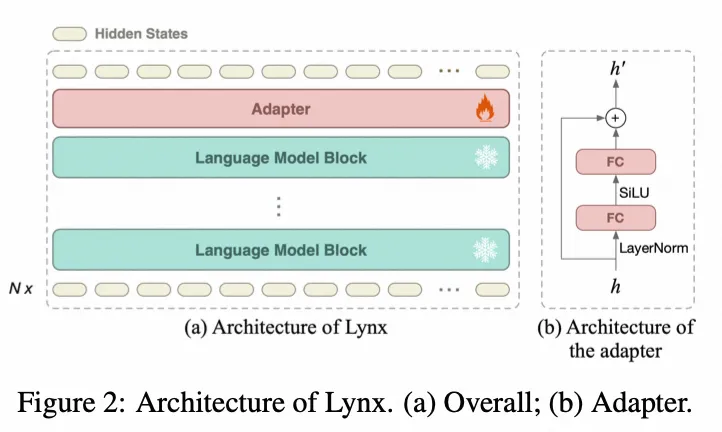
Lynx
- Paper:What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
- 作者:Yan Zeng 等,ByteDance Research 等
- 时间:2023.6.5
- 架构图:
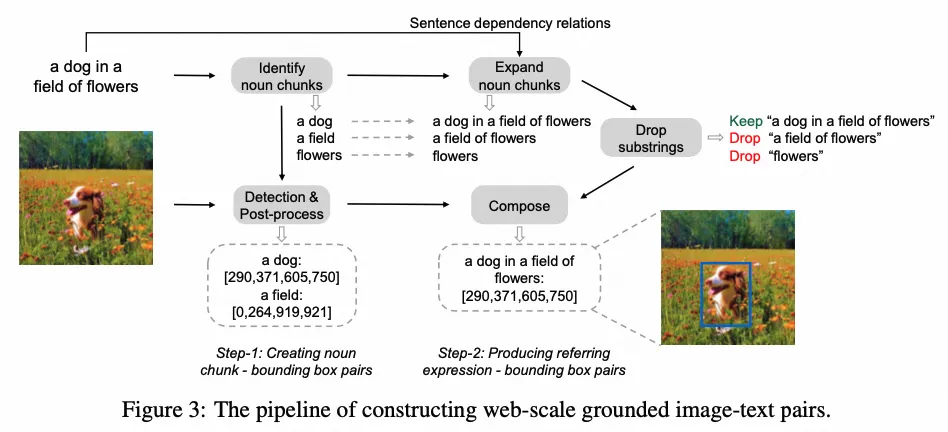
Kosmos-2
- Paper:Kosmos-2: Grounding Multimodal Large Language Models to the World
- 作者:Zhiliang Peng 等,Microsoft 等
- 时间:2023.6.27
- 架构图: